
使用Microsoft Agent Framework实现古文解读与地理位置标注
内容提要
该应用利用AI辅助古文解读,用户输入古文后可获得白话文及古代地名在现代地图上的位置。前端采用Blazor和腾讯地图,后端基于ASP.NET Core和ChatGPT-5实现解读功能,提升历史知识的理解与效率。
关键要点
-
该应用利用AI辅助古文解读,提升历史知识的理解与效率。
-
用户输入古文后可获得白话文及古代地名在现代地图上的位置。
-
前端采用Blazor和腾讯地图,后端基于ASP.NET Core和ChatGPT-5实现解读功能。
-
应用界面允许用户通过按钮获取解读结果和地名标注。
-
Web API微服务使用ASP.NET Core实现,调用部署在Azure的AI大语言模型。
-
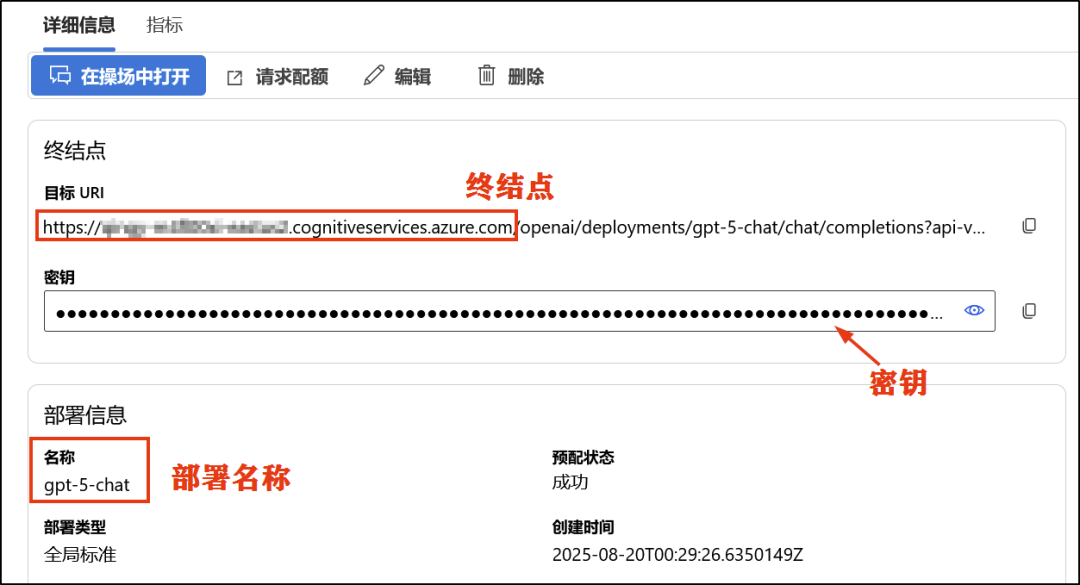
需要在Azure AI Foundry中获取LLM的部署名称、终结点和API密钥。
-
前端使用AntDesign Blazor构建页面布局,整合腾讯地图组件。
-
通过Javascript脚本实现地图操作和标注功能。
-
后端API处理用户请求并返回结构化数据,包括白话文和地名信息。
-
未来可考虑整合历史知识库以提高信息准确度。
延伸解读
应用背景与意义
在阅读古文时,古代地名的理解常常成为障碍,影响历史事件的理解。该应用通过AI技术,帮助用户快速获取古文的白话文翻译及地名标注,提升了历史学习的效率和准确性。
技术实现与挑战
该应用结合了Blazor、ASP.NET Core和ChatGPT-5等技术,构建了前后端分离的架构。实现过程中,开发者需注意API调用的准确性和数据结构的处理,以确保AI返回的结果能够被有效利用。
未来发展方向
虽然当前应用功能较为基础,但未来可以考虑整合历史知识库,以提高解读的准确性。此外,结合多种AI Agent和Workflow,可以实现更复杂的功能,进一步丰富用户体验。
延伸问答
这个应用如何帮助理解古文?
该应用利用AI辅助古文解读,用户输入古文后可获得白话文及古代地名在现代地图上的位置,从而提高历史知识的理解与效率。
应用的前端和后端使用了哪些技术?
前端采用Blazor和AntDesign Blazor,后端基于ASP.NET Core和ChatGPT-5实现解读功能。
如何在应用中标注古代地名?
用户输入古文后,应用通过后端API处理请求,返回古代地名及其现代位置的经纬度,并在腾讯地图上进行标注。
在Azure AI Foundry中需要哪些参数来部署大语言模型?
需要获取部署名称、终结点和API密钥,这些参数可以在Azure AI Foundry的模型页面中找到。
这个应用的未来发展方向是什么?
未来可考虑整合历史知识库以提高信息准确度,并可能整合多种Agent实现更高级的功能。
如何在前端调用后端API进行古文翻译?
前端通过HttpClient实例调用后端API,将古文内容作为请求发送,接收翻译结果并在页面上显示。
