
玩转 stream API
原文中文,约10100字,阅读约需24分钟。
📝
内容提要
本文介绍了流式API的基本概念及其在前端开发中的应用,强调流式处理在提高用户体验和避免内存溢出方面的优势。详细讲解了可读流、可写流和转换流的构造与使用方法,并指出队列策略在流数据处理中的重要性。通过实例展示流式处理与传统方法在处理大文件和日志输出时的效率差异。
🎯
关键要点
-
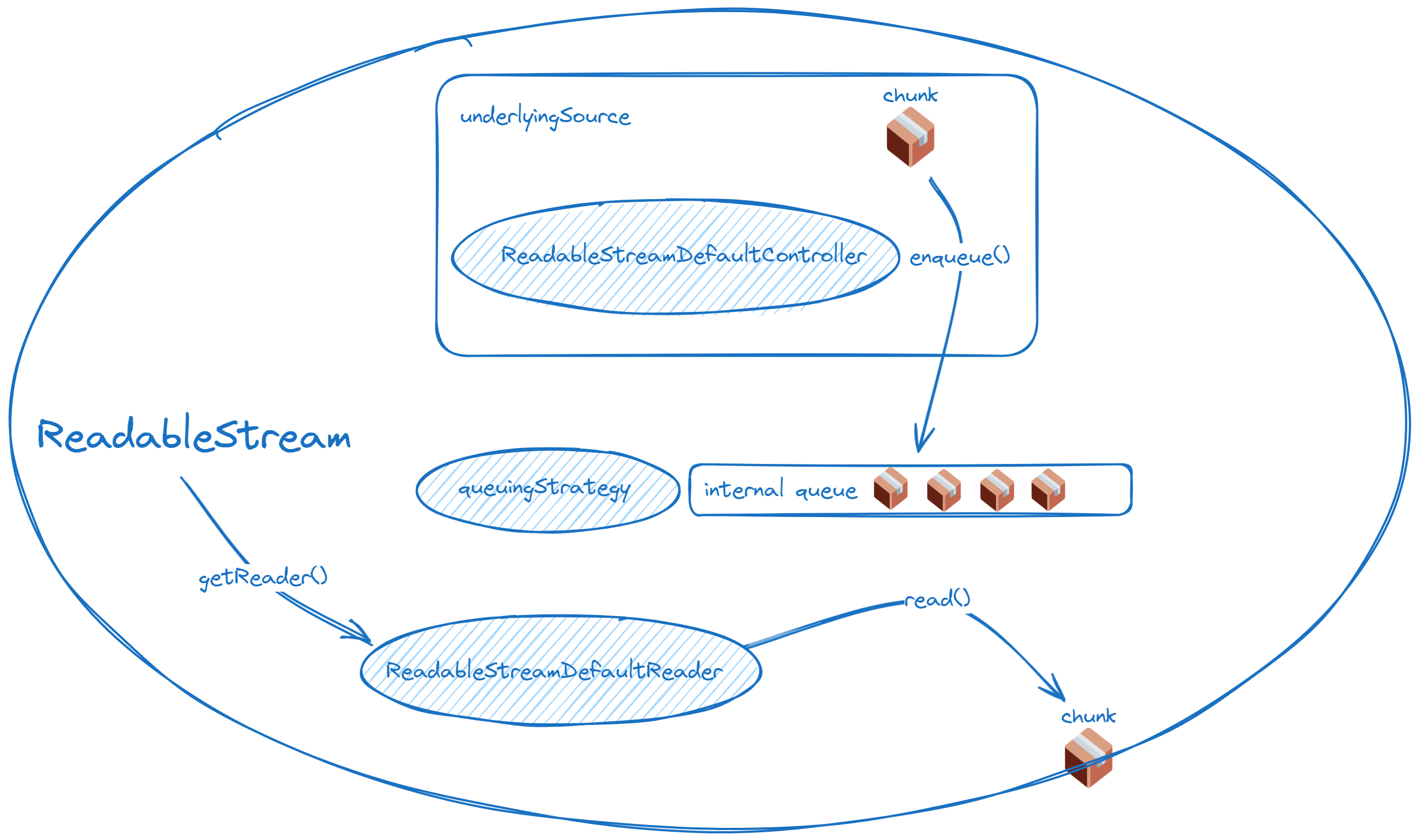
流式API允许连续的数据传输,防止内存溢出并提高用户响应速度。
-
可读流和可写流是流的基本构造,分别用于读取和写入数据。
-
队列策略在流数据处理中的重要性,通过highWaterMark控制流的队列大小。
-
转换流用于数据处理,可以通过管道操作函数连接可读流和可写流。
-
流式处理在处理大文件和日志输出时比传统方法更高效,能够即时展现内容。
❓
延伸问答
流式API的主要优势是什么?
流式API可以防止内存溢出并提高用户响应速度。
可读流和可写流的主要功能是什么?
可读流用于读取数据,而可写流用于写入数据。
队列策略在流数据处理中的作用是什么?
队列策略通过控制流的队列大小,提高数据处理效率,防止内存溢出。
转换流的用途是什么?
转换流用于数据处理,可以连接可读流和可写流进行数据转换。
流式处理与传统方法在处理大文件时有什么区别?
流式处理可以即时展现内容,而传统方法需要等待所有数据返回后再处理,效率较低。
如何使用管道操作函数连接流?
可以使用pipeTo()将可读流连接到可写流,使用pipeThrough()将可读流连接到转换流。
🏷️
