
InstructG2I:一种基于图形上下文感知的稳定扩散模型,用于从多模态属性图中合成图像
内容提要
伊利诺伊大学的研究人员开发了InstructG2I,通过图上下文感知扩散模型解决多模态属性图在图像生成中的挑战。该方法使用Graph-QFormer架构和个性化PageRank进行图采样,生成符合文本提示的图像。在多个数据集测试中,InstructG2I在CLIP和DINOv2得分上优于基线模型。
关键要点
-
多模态属性图(MMAG)在图像生成中具有广泛用途,但关注度不高。
-
MMAG以图形结构表示复杂实体之间的关系,节点包含图像和文本信息。
-
图形尺寸的爆炸性增长是由于组合复杂性,导致模型中引入的局部子图呈指数增长。
-
节点特征相互依赖,生成图像时需考虑文本和图像中实体之间的关系。
-
生成图像的可解释性需要控制,以遵循图形中实体之间的连接定义的模式。
-
伊利诺伊大学研究人员开发了InstructG2I,利用多模态图信息的图上下文感知扩散模型。
-
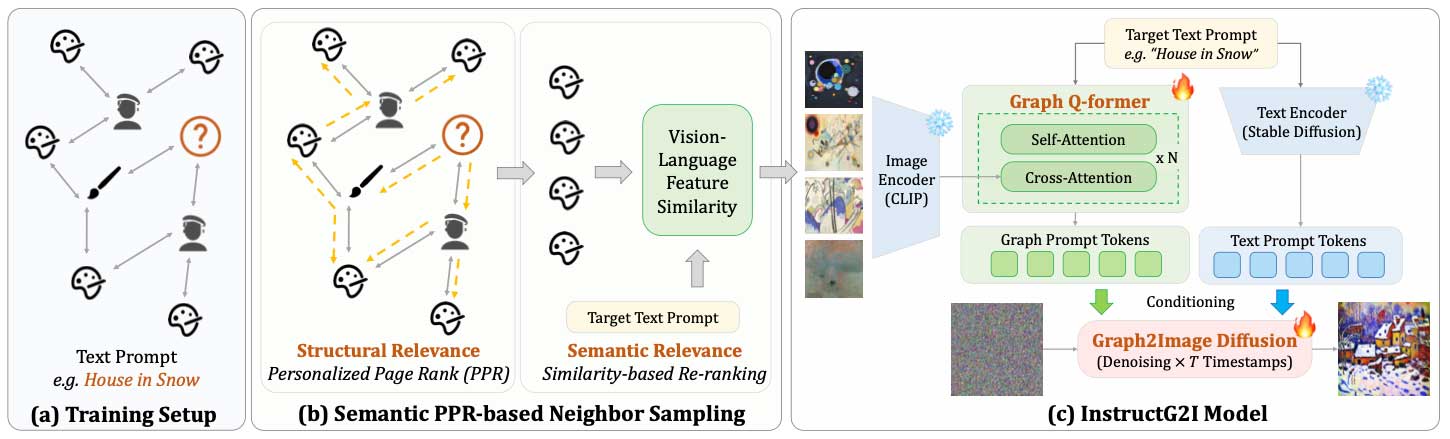
InstructG2I通过固定容量的图条件标记解决图空间复杂性,并使用个性化PageRank进行图采样。
-
Graph-QFormer架构解决了图实体依赖性问题,进一步改进了图标记。
-
InstructG2I通过可调边长引导图像生成,并采用基于PPR的邻居采样。
-
Graph-QFormer使用多头自注意力和多头交叉注意力捕获文本和图像的依赖关系。
-
InstructG2I在ART500K、Amazon和Goodreads三个数据集上进行了测试,表现显著优于基线模型。
-
在CLIP和DINOv2得分方面,InstructG2I优于所有基线模型。
-
InstructG2I生成的图像最符合文本提示和上下文语义,有效解决了MMAG中的主要挑战。
-
未来将有更多机会将图形纳入图像生成,处理MMAG上图像和文本之间的复杂关系。
延伸问答
InstructG2I模型的主要功能是什么?
InstructG2I模型通过图上下文感知的扩散模型,解决多模态属性图在图像生成中的挑战,生成符合文本提示的图像。
多模态属性图(MMAG)在图像生成中面临哪些挑战?
MMAG面临图形尺寸爆炸、节点特征相互依赖和生成图像可解释性控制等挑战。
InstructG2I是如何处理图形尺寸爆炸问题的?
InstructG2I通过将图中的上下文压缩为固定容量的图条件标记来解决图空间复杂性问题。
Graph-QFormer架构在InstructG2I中起什么作用?
Graph-QFormer架构解决了图实体依赖性问题,进一步改进了图标记,帮助捕获文本和图像之间的依赖关系。
InstructG2I在测试中表现如何?
InstructG2I在ART500K、Amazon和Goodreads三个数据集上测试,表现显著优于所有基线模型,尤其在CLIP和DINOv2得分方面。
未来InstructG2I的应用前景如何?
未来将有更多机会将图形纳入图像生成,处理MMAG上图像和文本之间的复杂关系。
