
redis之主从库同步
内容提要
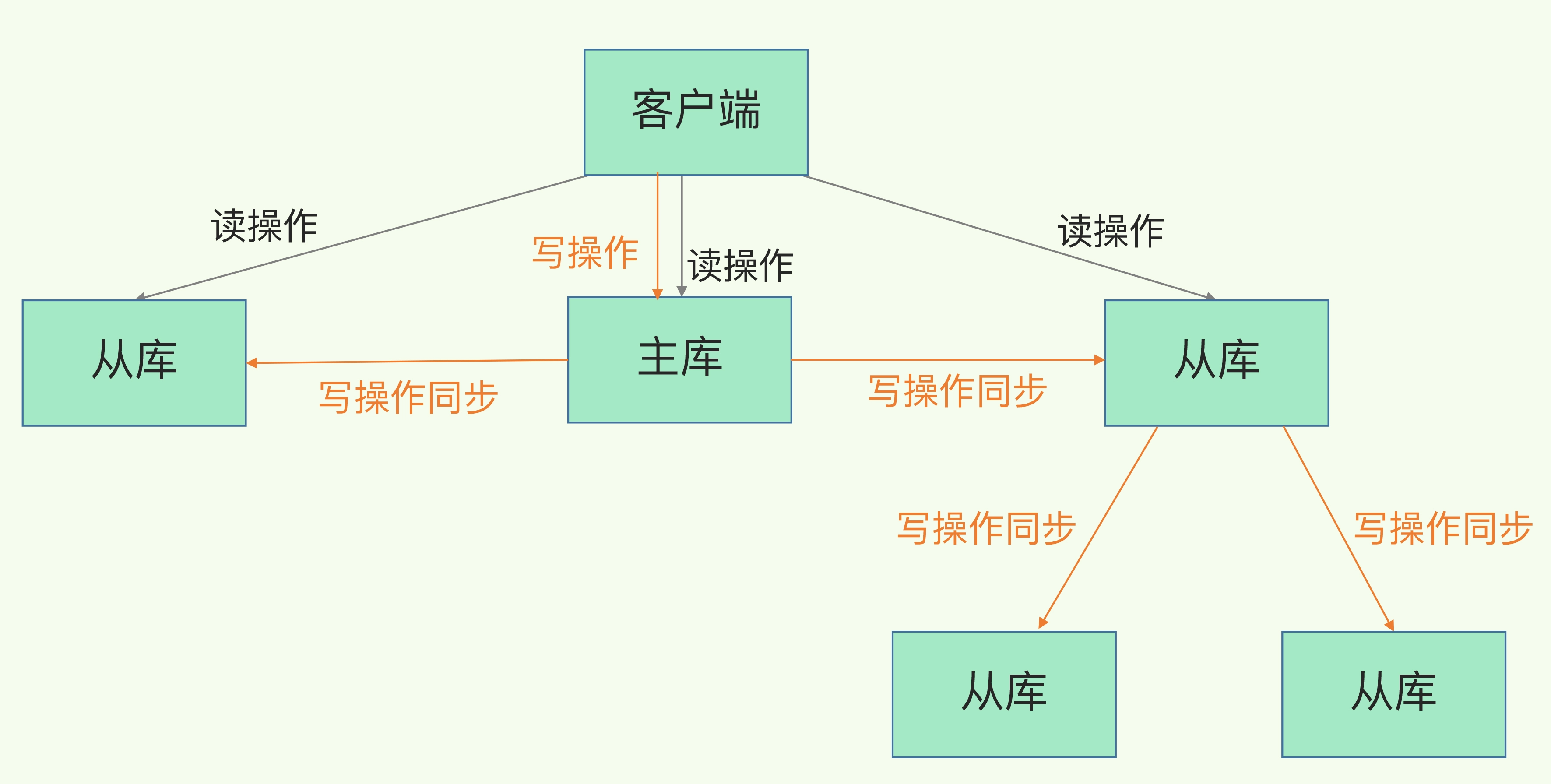
本文介绍了Redis主从库的数据同步机制,强调通过读写分离模式确保数据一致性。主库负责写入,而从库负责读取,避免数据不一致。详细阐述了全量复制和增量复制的过程,增量复制通过长连接减少全量复制频率,以实现高效同步。
关键要点
-
Redis主从库的数据同步机制确保数据副本的一致性。
-
主库负责写入,从库负责读取,采用读写分离模式。
-
读写分离避免了数据不一致的问题,提升了性能。
-
全量复制过程包括从库发送psync命令、主库生成RDB文件、从库读取RDB文件。
-
全量复制会对主库造成压力,可以通过选择高内存的从库进行级联复制来减轻压力。
-
增量复制通过长连接减少全量复制的频率,避免频繁的CPU消耗和主线程阻塞。
-
增量复制过程中,主库和从库使用缓冲区记录操作命令,确保数据同步。
-
如果主从库长期断开,可能会覆盖旧数据,需重新发起全量复制。
-
RDB文件比AOF文件更小且恢复速度快,因此全量复制使用RDB而非AOF。
延伸解读
主从库的读写分离优势
Redis的主从库采用读写分离模式,主库负责写入,从库负责读取。这种设计有效避免了数据不一致的问题,提升了系统性能。读写分离不仅减轻了主库的负担,还能通过多个从库分担读取请求,提高了整体的响应速度。
全量复制与增量复制的选择
全量复制通过生成RDB文件进行数据同步,但会对主库造成一定压力。为了减少这种压力,可以选择内存资源较高的从库进行级联复制。增量复制则通过长连接减少全量复制的频率,确保数据同步的高效性,避免频繁的CPU消耗和主线程阻塞。
网络中断的风险管理
在主从库的增量复制过程中,网络中断可能导致数据丢失或覆盖。为了应对这种情况,Redis使用环形缓冲区记录操作命令,确保在恢复连接时能够同步未传输的命令。如果长时间断开,可能需要重新发起全量复制,因此监控网络状态至关重要。
延伸问答
Redis主从库的读写分离模式是如何工作的?
在读写分离模式中,主库负责写入数据,而从库负责读取数据,这样可以避免数据不一致的问题。
全量复制的过程是怎样的?
全量复制的过程包括从库发送psync命令,主库生成RDB文件并发送给从库,从库清空当前数据并读取RDB文件完成同步。
如何减少主库在全量复制时的压力?
可以选择高内存的从库进行级联复制,由从库生成RDB文件并传输给其他从库,从而减轻主库的压力。
增量复制是如何实现的?
增量复制通过建立长连接,主库将新的操作命令记录到缓冲区,并在恢复连接时将未同步的命令发送给从库。
为什么全量复制使用RDB而不是AOF?
因为RDB文件较小且恢复速度快,而AOF文件较大且恢复速度慢,使用RDB可以减少带宽消耗。
主从库长期断开后会发生什么?
如果主从库长期断开,可能会覆盖旧数据,需要重新发起全量复制以确保数据一致性。
