
一款基于.NET开源的爬虫库,小白也能直接上手,简单、全能,高效
内容提要
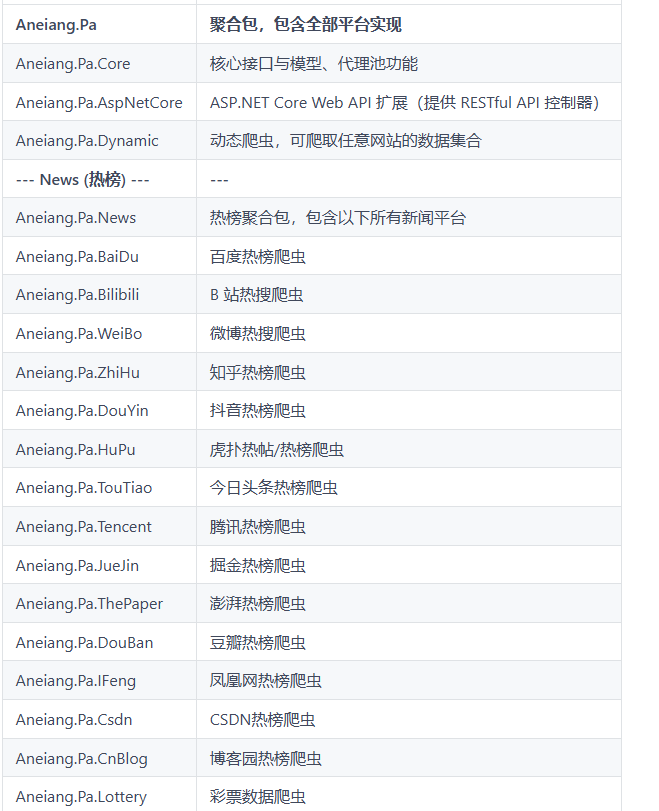
这是一款基于.NET的开源爬虫库,简化了数据抓取过程,适配多个主流平台,支持动态模型抓取和RESTful接口,具备多种缓存策略和代理池功能,降低IP封禁风险,使用简单,学习成本低,适合快速集成和数据分析。
关键要点
-
这是一款基于.NET的开源爬虫库,简化了数据抓取过程。
-
支持多个主流平台的热榜数据抓取,包括微博、知乎、B站等。
-
具备动态模型抓取能力,适应不规则数据结构,无需反复定义实体类。
-
内置ASP.NET Core WebAPI托管能力,支持一键搭建RESTful接口。
-
提供多种缓存策略和代理池功能,降低IP封禁风险。
-
使用简单,学习成本低,适合个人开发者和内容运营者快速集成和数据分析。
延伸解读
适用场景分析
这款基于.NET的开源爬虫库非常适合个人开发者和内容运营者。无论是快速抓取各大平台的热榜数据,还是进行数据分析和选题参考,都能显著提高工作效率。对于需要定时爬取和规避IP封禁的业务场景,该库的代理池和缓存策略也提供了有效的解决方案。
技术特点与优势
该爬虫库的动态模型抓取能力使其能够灵活适应不规则数据结构,避免了反复定义实体类的麻烦。此外,内置的ASP.NET Core WebAPI托管功能,简化了RESTful接口的搭建过程,用户只需几行代码即可完成数据抓取,降低了技术门槛。
风险与注意事项
尽管该爬虫库提供了多种防封禁机制,但用户仍需遵循平台的访问规则,建议抓取间隔至少为5分钟。合理使用代理池和缓存策略可以有效降低IP封禁风险,确保爬虫的稳定性和生命周期。
延伸问答
这款爬虫库适合哪些用户使用?
这款爬虫库适合个人开发者、内容运营者和需要快速集成爬虫能力的后端项目开发者。
这款爬虫库支持哪些平台的数据抓取?
该爬虫库支持微博、知乎、B站、百度、抖音等多个主流平台的数据抓取。
使用这款爬虫库的学习成本高吗?
使用这款爬虫库的学习成本低,适合初学者快速上手。
爬虫库有哪些技术特点?
该爬虫库具有动态模型抓取、内置WebAPI托管、多种缓存策略和代理池等技术特点。
如何降低IP封禁风险?
可以通过使用内置的代理池和设置抓取间隔来降低IP封禁风险。
这款爬虫库的使用复杂度如何?
这款爬虫库的使用复杂度极低,几行代码即可完成抓取。
