
读 Cloudflare Outage February 20 2026
内容提要
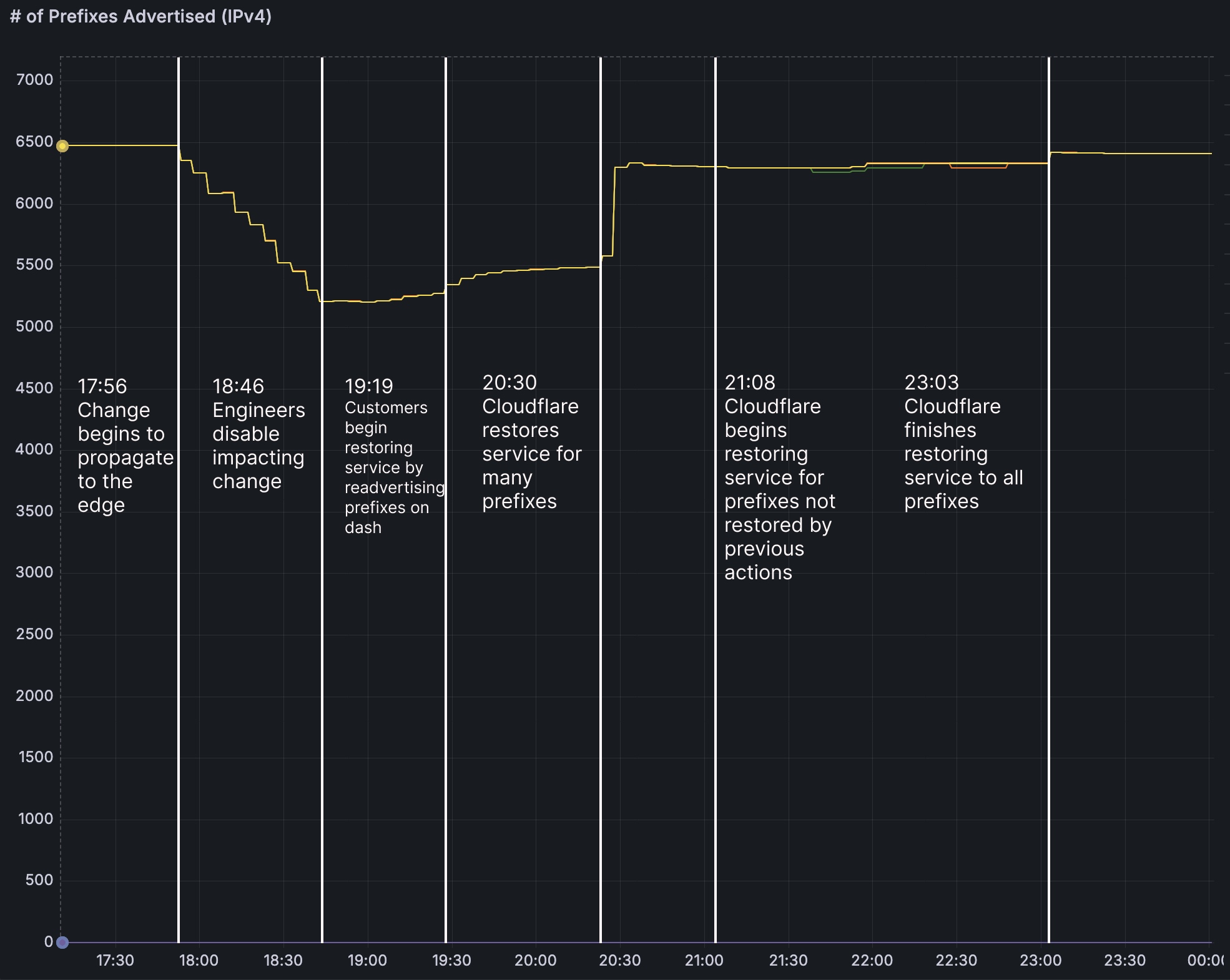
2026年2月20日,Cloudflare发生了6小时的故障,因内部变更错误撤回部分用户的路由前缀,导致IP不可达。故障期间,用户请求未能找到备用路径,最终超时失败。故障后,Cloudflare计划改进API标准化和监控机制,以降低未来风险。
关键要点
-
2026年2月20日,Cloudflare发生了6小时的故障,因内部变更错误撤回部分用户的路由前缀,导致IP不可达。
-
故障期间,用户请求未能找到备用路径,最终超时失败,用户体验受到影响。
-
故障的根本原因是一个简单的参数错误,导致API返回了错误的前缀列表。
-
Cloudflare计划改进API标准化和监控机制,以降低未来风险,包括增加变更的中间态和自动回滚能力。
-
故障复盘强调了在生产环境中对删除操作的谨慎,以及通过监控和可回滚机制来减少风险的重要性。
延伸解读
故障的根本原因
此次Cloudflare故障的根本原因是一个简单的参数错误,导致API返回了错误的前缀列表。这提醒我们在进行系统变更时,必须对每一个参数进行严格的验证和测试,以避免因小失大。
用户体验的影响
故障期间,用户请求未能找到备用路径,导致网页请求超时失败,用户体验受到严重影响。这强调了在设计网络服务时,必须考虑到冗余和容错机制,以确保在故障发生时仍能提供基本服务。
未来的改进措施
Cloudflare计划通过改进API标准化和监控机制来降低未来风险,包括增加变更的中间态和自动回滚能力。这些措施将有助于提高系统的稳定性和可靠性,值得其他企业借鉴。
延伸问答
Cloudflare在2026年2月20日发生了什么故障?
Cloudflare在2026年2月20日发生了6小时的故障,因内部变更错误撤回部分用户的路由前缀,导致IP不可达。
这次故障的根本原因是什么?
故障的根本原因是一个简单的参数错误,导致API返回了错误的前缀列表。
故障期间用户的体验如何?
故障期间,用户请求未能找到备用路径,最终超时失败,导致网页请求卡死。
Cloudflare计划如何改进以降低未来故障风险?
Cloudflare计划改进API标准化和监控机制,包括增加变更的中间态和自动回滚能力。
故障发生后,Cloudflare采取了哪些恢复措施?
故障发生后,Cloudflare进行了变更回滚,并手动恢复了部分受影响用户的服务。
在生产环境中,如何减少删除操作的风险?
在生产环境中,所有删除相关的操作都应该谨慎进行,并通过监控和可回滚机制来减少风险。
