
一日一技:Requests被网站识别怎么办?
💡
原文中文,约2100字,阅读约需5分钟。
📝
内容提要
该文章介绍了使用curl_cffi库修改请求头以避免被识别为爬虫。只需修改代码第一行和在requests.get中加入参数impersonate="chrome110"即可。curl_cffi兼容Requests语法,支持Asyncio。
🎯
关键要点
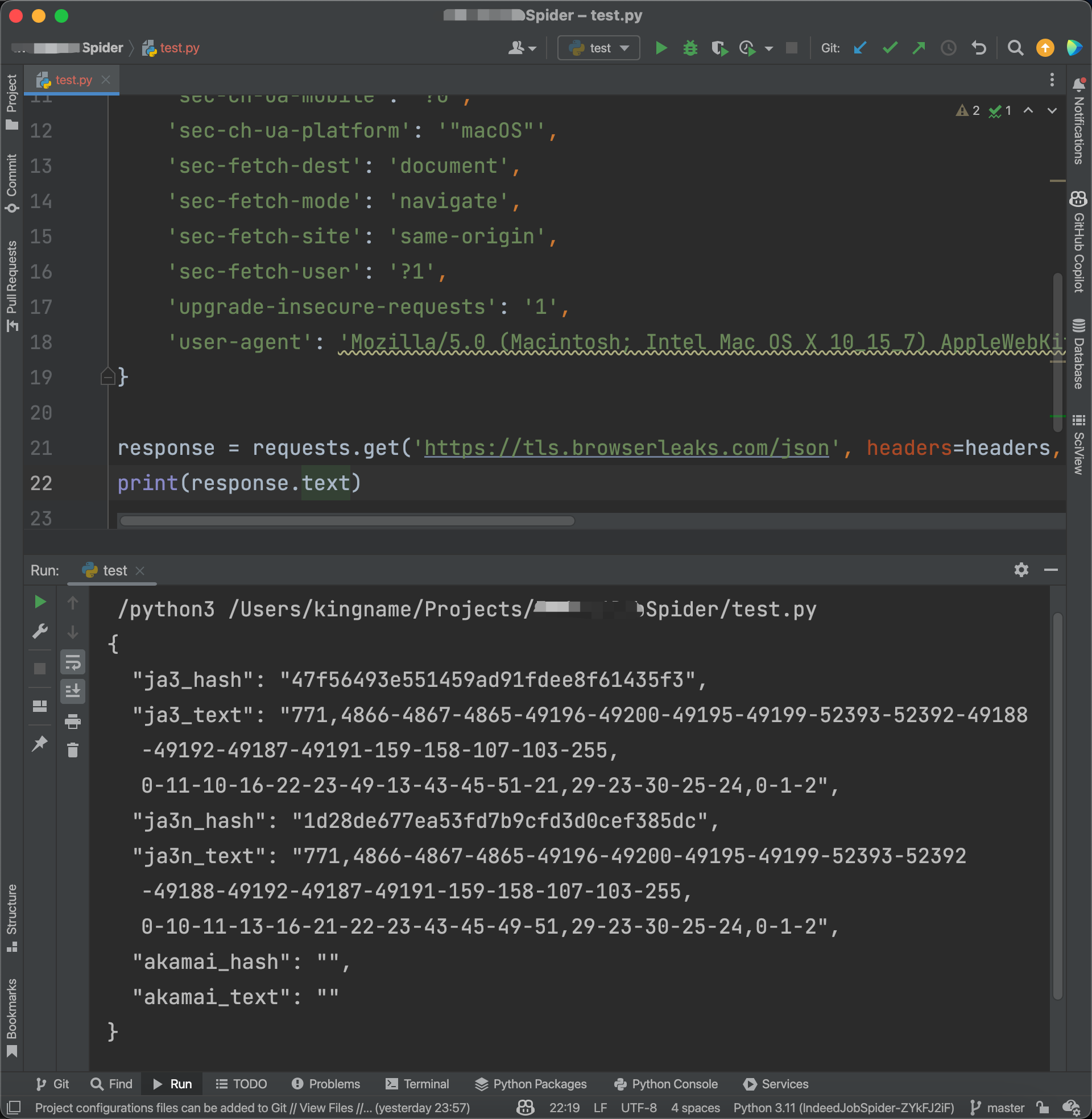
- 许多网站通过JA3或其他指纹信息识别请求是否由Requests发起。
- 修改两行代码可以简单地绕过JA3和Akamai的检测。
- 需要安装curl_cffi库,并将import requests改为from curl_cffi import requests。
- 在requests.get中添加参数impersonate='chrome110'以伪装请求。
- curl_cffi兼容Requests语法,并支持Asyncio。
- 使用AsyncSession可以实现异步请求。
➡️
