
介绍查询管道
内容提要
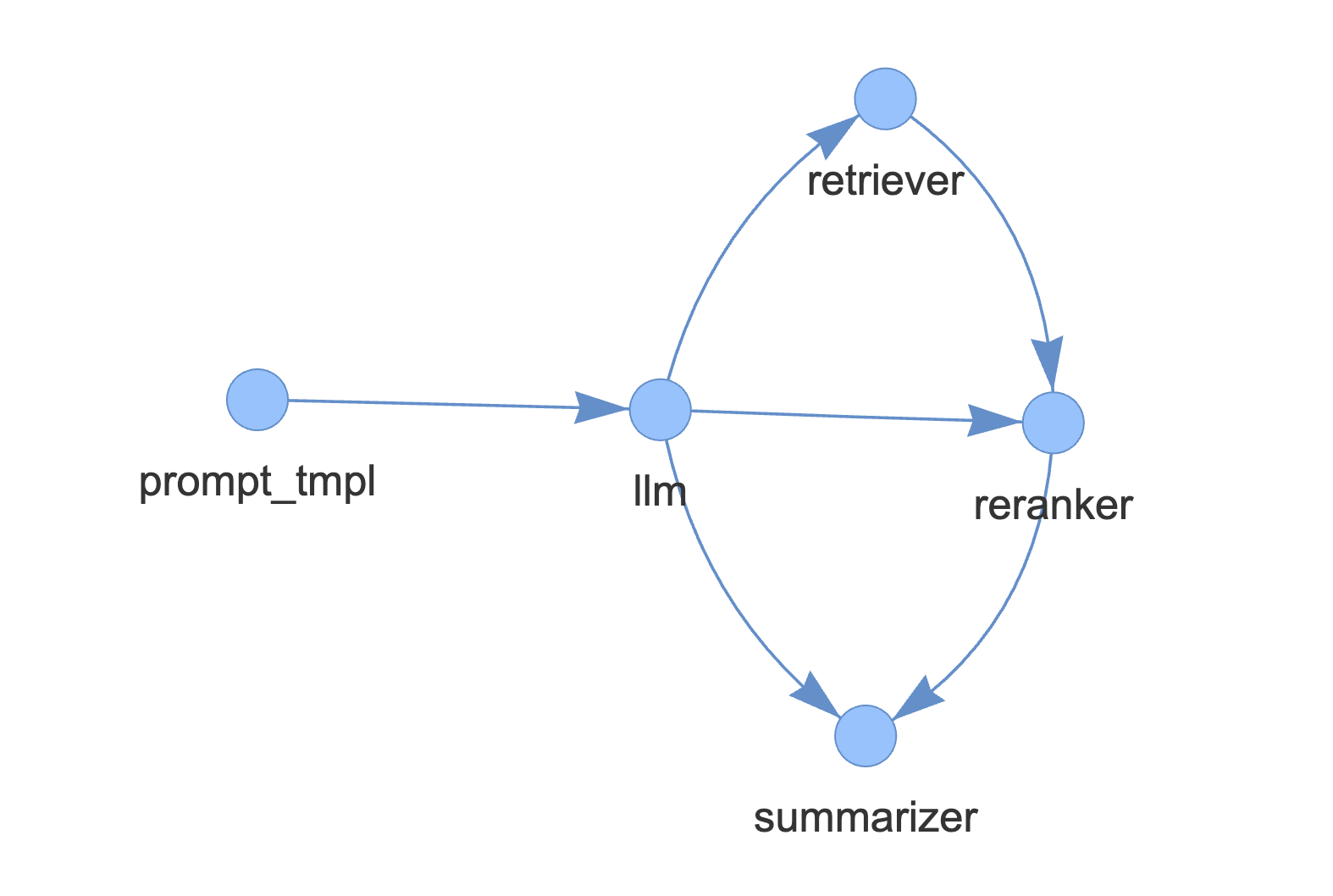
LlamaIndex推出了Query Pipelines,一个新的声明式API,简化了数据查询工作流的构建。用户可以通过组合不同模块(如LLMs、检索器等)创建复杂的查询图,支持多种用例,提升了代码可读性,减少了样板代码,并支持回调集成,便于监控和优化查询流程。
关键要点
-
LlamaIndex推出了Query Pipelines,一个新的声明式API,简化了数据查询工作流的构建。
-
用户可以通过组合不同模块(如LLMs、检索器等)创建复杂的查询图,支持多种用例。
-
QueryPipeline支持回调集成,便于监控和优化查询流程。
-
QueryPipeline允许用户以更少的代码行表达常见查询工作流,提高代码可读性。
-
用户可以使用QueryPipeline创建顺序链或有向无环图(DAG)来构建查询工作流。
-
QueryPipeline支持多种LlamaIndex模块,包括LLMs、提示、查询引擎等,用户也可以定义自己的模块。
延伸问答
什么是Query Pipelines?
Query Pipelines是LlamaIndex推出的一种新的声明式API,用于简化数据查询工作流的构建。
Query Pipelines支持哪些模块?
Query Pipelines支持多种LlamaIndex模块,包括LLMs、提示、查询引擎、检索器等,用户也可以定义自己的模块。
使用Query Pipelines有什么好处?
使用Query Pipelines可以用更少的代码行表达常见查询工作流,提高代码可读性,并支持回调集成以便于监控和优化。
如何创建一个DAG结构的查询工作流?
可以通过定义模块并使用add_link方法来创建DAG结构的查询工作流,指定模块之间的关系。
Query Pipelines与IngestionPipeline有什么区别?
Query Pipelines在查询阶段操作,而IngestionPipeline在数据摄取阶段操作,二者有不同的应用场景。
如何使用Query Pipelines进行响应合成?
可以通过将LLM与响应合成器模块结合使用,在Query Pipelines中实现响应合成。
