
Vec-Tok-VC+: 双重训练策略下基于渐进式损失约束和残差增强的鲁棒零样本语音转换 | INTERSPEECH2024
原文中文,约8300字,阅读约需20分钟。
📝
内容提要
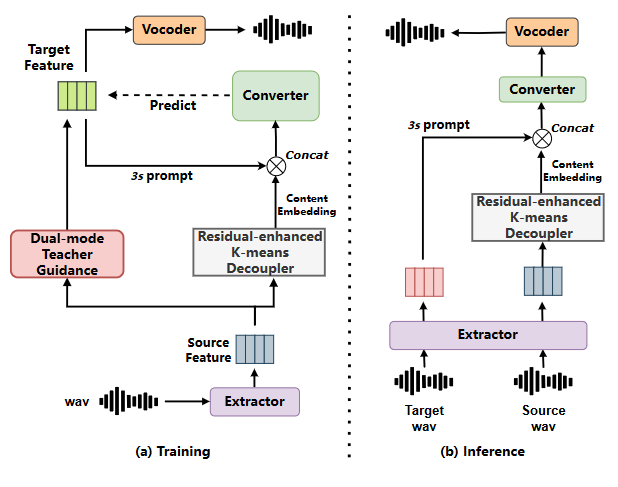
西工大音频语音与语言处理研究组与喜马拉雅合作提出了鲁棒零样本语音转换模型Vec-Tok-VC+,通过渐进式损失约束和残差增强方法解决了不匹配问题和语义信息损失,提升了转换的自然度和相似度。该模型在实验中表现优于其他模型。
🎯
关键要点
-
西工大音频语音与语言处理研究组与喜马拉雅合作提出鲁棒零样本语音转换模型Vec-Tok-VC+。
-
Vec-Tok-VC+通过渐进式损失约束和残差增强方法解决训练和推理之间的不匹配问题。
-
该模型有效减轻了解耦过程中的语义信息损失,提升了转换的自然度和相似度。
-
零样本语音转换旨在保留语言内容的同时,将源说话人语音转换为任意目标说话人的语音。
-
Vec-Tok-VC+在实验中表现优于其他模型,尤其在自然度和相似度方面。
-
模型采用双模式训练策略,结合教师指导模块和多码本渐进式损失约束。
-
实验使用了19,000小时的中英语音数据,验证了模型的有效性和鲁棒性。
❓
延伸问答
Vec-Tok-VC+模型的主要创新点是什么?
Vec-Tok-VC+模型通过双模式训练策略结合渐进式损失约束和残差增强方法,解决了训练和推理之间的不匹配问题,减轻了语义信息损失,提升了转换的自然度和相似度。
Vec-Tok-VC+在实验中表现如何?
在实验中,Vec-Tok-VC+在自然度和相似度方面均优于其他对比模型,显示出其在零样本语音转换中的有效性。
零样本语音转换的主要挑战是什么?
零样本语音转换的主要挑战在于对未见说话人音色的建模以及解耦源语义内容的过程。
Vec-Tok-VC+模型如何处理语义信息损失?
该模型通过残差增强的K-Means聚类来编码内容的残差信息,从而减轻解耦过程中的语义信息损失。
Vec-Tok-VC+模型的训练数据来源是什么?
模型的训练数据包括19,000小时的中英语音数据,涵盖开源英文数据集LibriTTS、Gigaspeech,以及内部收集的中文有声书数据集。
Vec-Tok-VC+模型的应用场景有哪些?
该模型可应用于隐私保护、电影配音等场景,旨在将源说话人的语音转换为任意目标说话人的音色,同时保留语言内容。
🏷️
