
数据泄露如何悄然破坏你的模型的三种微妙方式(及其预防措施)
内容提要
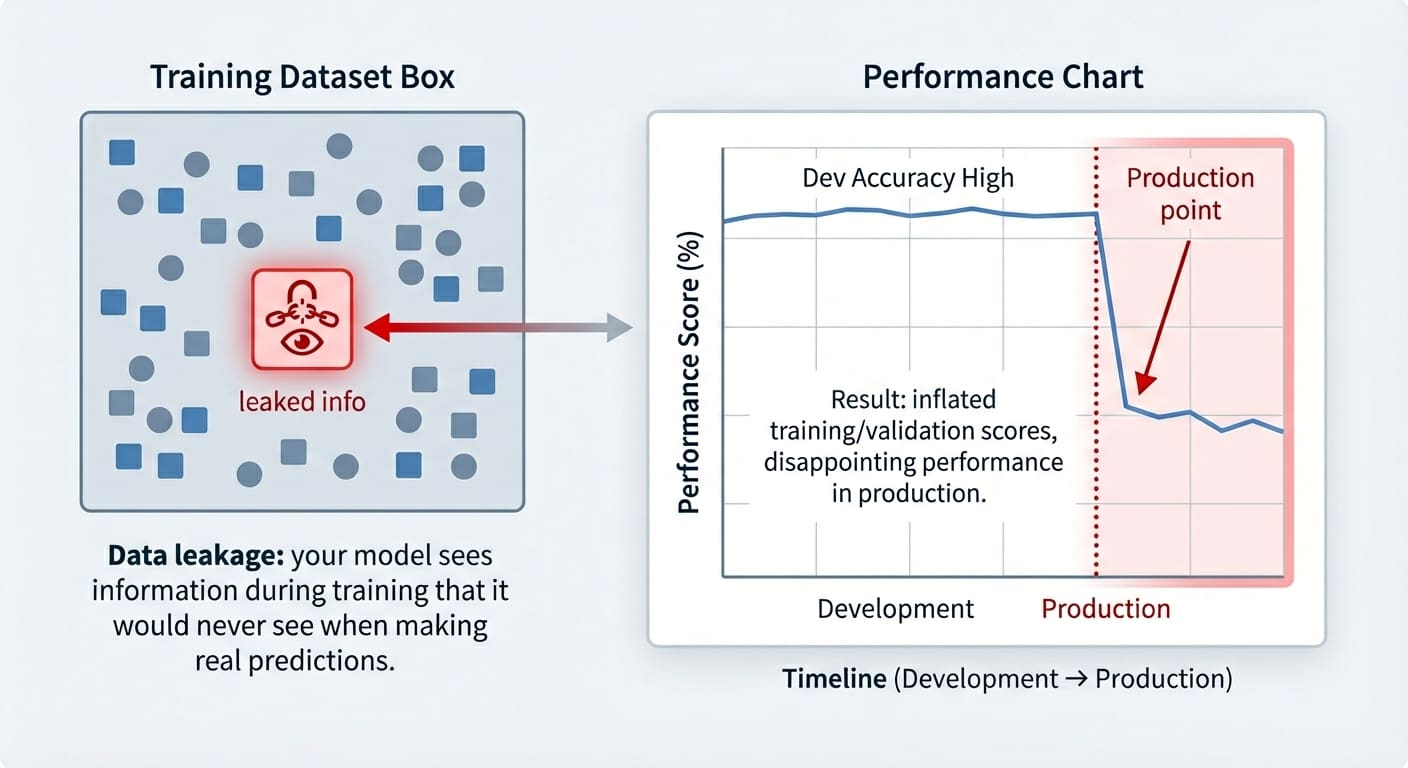
数据泄露是机器学习中的常见问题,指训练数据中包含不应知晓的信息,导致模型在训练和验证集上表现良好,但在新数据上效果差。文章讨论了三种泄露场景:目标泄露、训练-测试污染和时间序列中的时间泄露,并提供了防止这些问题的策略。
关键要点
-
数据泄露是机器学习中的常见问题,指训练数据中包含不应知晓的信息。
-
数据泄露导致模型在训练和验证集上表现良好,但在新数据上效果差。
-
文章讨论了三种数据泄露场景:目标泄露、训练-测试污染和时间序列中的时间泄露。
-
目标泄露是指特征中包含直接或间接揭示目标变量的信息。
-
训练-测试污染发生在数据准备顺序不正确时,可能会将测试数据的信息引入训练集中。
-
时间序列中的时间泄露是指未来信息被泄露到训练集中,影响模型预测能力。
-
数据泄露与过拟合不同,过拟合是模型记住训练集中的特定模式,而数据泄露是模型接触到不应知晓的信息。
-
防止数据泄露的策略包括仔细分析目标与特征之间的相关性,检查特征权重等。
-
在数据预处理时,正确的顺序非常重要,应该先分割数据再进行缩放。
-
在时间序列数据中,应该使用描述过去的信息,而不是未来的信息来构建预测模型。
延伸解读
数据泄露的潜在风险
数据泄露可能导致模型在训练和验证集上表现良好,但在实际应用中却效果不佳。这种现象可能在模型投入生产后才显现,因此在模型开发阶段必须高度重视数据泄露的风险,确保模型的泛化能力。
防止数据泄露的最佳实践
为了有效防止数据泄露,建议在数据预处理时遵循正确的顺序,先进行数据分割再进行缩放。此外,特征工程时应仔细分析特征与目标变量之间的关系,避免引入可能导致目标泄露的特征。
时间序列数据的特殊注意事项
在处理时间序列数据时,必须避免使用未来信息来预测过去的值。应优先使用描述过去的特征,如滚动统计量,以确保模型的预测能力不受未来信息的影响。
延伸问答
什么是数据泄露,它对机器学习模型有什么影响?
数据泄露是指训练数据中包含不应知晓的信息,导致模型在训练和验证集上表现良好,但在新数据上效果差。
目标泄露是什么,如何避免?
目标泄露是指特征中包含直接或间接揭示目标变量的信息。避免方法包括仔细分析目标与特征之间的相关性,移除相关特征。
训练-测试污染是如何发生的?
训练-测试污染发生在数据准备顺序不正确时,例如在分割数据之前对整个数据集进行缩放。
时间序列中的时间泄露是什么?
时间泄露是指未来信息被泄露到训练集中,影响模型的预测能力,例如使用未来的价格来预测过去的价格。
如何防止数据泄露?
防止数据泄露的策略包括正确的预处理顺序、分析特征权重、以及在时间序列中使用过去的信息而非未来的信息。
数据泄露与过拟合有什么区别?
数据泄露是模型接触到不应知晓的信息,而过拟合是模型记住训练集中的特定模式,二者的后果和表现不同。
