

我对子解释器的看法是错的
💡
原文英文,约1600词,阅读约需6分钟。
📝
内容提要
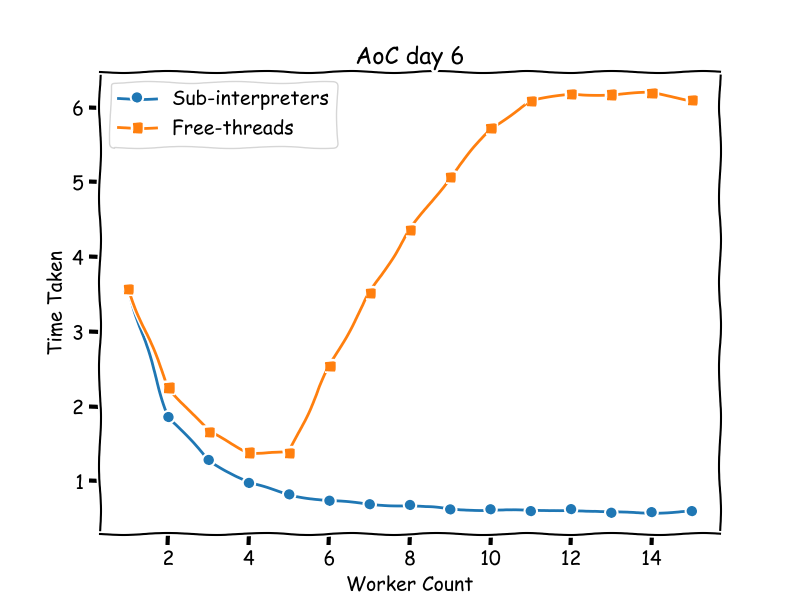
文章探讨了Python中的子解释器及其性能问题。实验表明,使用`InterpreterPoolExecutor`时,数据共享机制会影响性能,尤其是`memoryview`的使用能提高效率。尽管子解释器功能强大,但使用复杂,作者认为标准库功能已足够,未来将专注于增强现有特性。
🎯
关键要点
- 文章探讨了Python中的子解释器及其性能问题。
- 使用`InterpreterPoolExecutor`时,数据共享机制会影响性能,特别是`memoryview`的使用能提高效率。
- 作者认为标准库功能已足够,未来将专注于增强现有特性。
- 实验表明,使用子解释器时,性能表现优于多线程实现。
- 在使用`InterpreterPoolExecutor`时,数据在解释器之间是复制而非引用传递。
- 使用`memoryview`可以避免数据复制,提高性能。
- 作者对函数传递和加载机制的理解存在误区,pickle在函数传递中只保存函数名而非代码。
- 建议使用`InterpreterPoolExecutor`来简化子解释器的使用。
- 对于复杂的同步需求,可以在asyncio中运行Executors。
- 作者认为`aiointerpreters`是多余的,标准库的功能已足够。
- 发现当前的executor实现基于`ThreadPoolExecutor`,可以创建混合executor以提高灵活性。
- 作者正在开发一个分发异步任务到不同解释器的Runner。
- 并行处理在Python中仍处于初期阶段,缺乏明确的解决方案。
➡️
