
从零学习 Hypothetical Document Embeddings (HyDE) - 1
内容提要
这篇论文介绍了一种评估RAG技术的方法,提到HyDE和LLM re-rank可以提高检索精度。RAG是一种基于检索的生成式模型,结合了检索和生成的优点。HyDE是一种基于RAG的模式,通过比较真实文档和假设文档的差异来提高模型的泛化能力。将HyDE和RAG结合可以提高生成性能和可靠性。
关键要点
-
这篇论文介绍了一种评估RAG技术的方法,提到HyDE和LLM re-rank可以提高检索精度。
-
RAG是一种基于检索的生成式模型,结合了检索和生成的优点。
-
HyDE通过比较真实文档和假设文档的差异来提高模型的泛化能力。
-
RAG模型由检索器和生成器两部分组成,能够动态从外部知识库中检索信息。
-
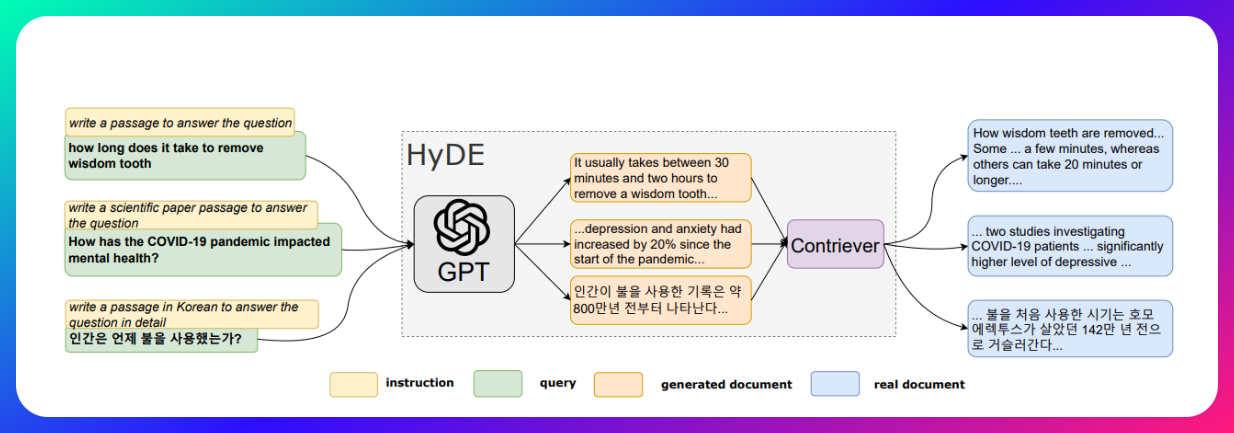
HyDE使用LLM生成假设文档,与知识库中的文档进行比较,帮助RAG处理知识库中不存在的数据。
-
HyDE能够捕捉文本语义和上下文信息,提高RAG模型的准确性和可靠性。
-
HyDE与RAG结合可以提升生成性能和增强模型的可靠性。
-
文章将以LangChain为例,演示如何在实际应用中使用HyDE。
延伸问答
HyDE是什么,它如何提高RAG模型的性能?
HyDE(Hypothetical Document Embeddings)是一种基于RAG模型的模式,通过生成假设文档并与真实文档比较,来提高模型的泛化能力和生成性能。
RAG模型的基本组成部分是什么?
RAG模型由检索器和生成器两部分组成,检索器从知识库中检索信息,生成器负责生成答案。
HyDE如何处理知识库中不存在的数据?
HyDE通过生成假设文档,帮助RAG模型处理知识库中不存在的数据,从而提高模型的准确性和可靠性。
RAG模型与传统大语言模型相比有什么优势?
RAG模型结合了检索和生成的优点,能够动态从外部知识库中检索信息,提高生成内容的准确性和可靠性。
HyDE的核心思想是什么?
HyDE的核心思想是通过对比真实文档和假设文档的差异,学习出更好捕捉文本语义和上下文信息的文档向量表示。
这篇文章将如何展示HyDE的实际应用?
文章将以LangChain为例,演示如何在实际应用中使用HyDE。
