
从K-mer到自适应词元:厦门大学林琛团队让AI自动学习「基因功能边界」
内容提要
高通量测序技术与人工智能结合,推动基因组学发展。厦门大学林琛教授提出自适应分词机制,利用AI高效解读DNA序列,提升基因功能预测与疾病标志物识别能力。GenArt模型在无监督条件下自动识别生物功能边界,为基因组研究提供新思路。
关键要点
-
高通量测序技术与人工智能结合,推动基因组学发展。
-
厦门大学林琛教授提出自适应分词机制,利用AI高效解读DNA序列。
-
GenArt模型在无监督条件下自动识别生物功能边界,为基因组研究提供新思路。
-
现有分词策略在DNA序列应用中存在根本性缺陷,限制了模型的泛化能力。
-
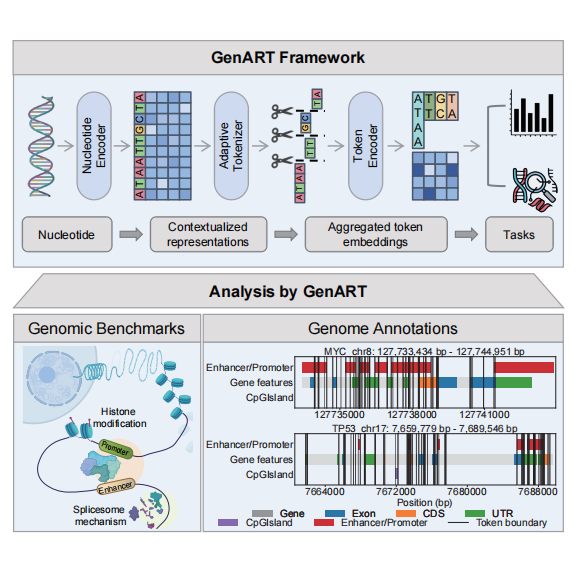
GenArt模型通过自适应变长分词架构,能够自动发掘具有生物学意义的词源边界。
-
模型在多个下游任务中表现优越,尤其在长序列任务上稳定性强。
-
验证结果显示,模型能够有效捕获功能元件边界,召回率显著提高。
-
研究填补了强监督分割与纯统计语言模型之间的空白,具有广泛的参考意义。
延伸解读
自适应分词的创新意义
林琛教授提出的自适应分词机制,突破了传统分词策略在DNA序列应用中的局限性。通过动态调整分词粒度,模型能够更精准地捕捉生物功能单元,提升基因组研究的效率。这一创新为基因组学提供了新的研究思路,尤其在处理复杂的基因序列时,能够有效提高模型的泛化能力。
GenArt模型的优势与挑战
GenArt模型在多个下游任务中表现优越,尤其在长序列任务上展现出稳定性。然而,尽管模型在无监督条件下取得了显著成果,仍需注意其对生物学功能的验证和上下文窗口的扩展限制。未来的研究可以探索更高效的架构,以进一步提升模型的性能和适用性。
基因组学的未来发展方向
随着AI技术的不断进步,基因组学正朝着从数据读取向功能理解转变。林琛教授的研究不仅填补了强监督与纯统计模型之间的空白,还为其他领域的序列建模提供了借鉴。未来,跨学科的合作将是推动基因组学和生物医学研究的重要动力。
延伸问答
GenArt模型的核心特点是什么?
GenArt模型支持自适应变长分词,能够在无监督条件下自动发掘具有生物学意义的词源边界。
林琛教授提出的自适应分词机制有什么优势?
自适应分词机制能够更精准地捕捉DNA序列中的功能单元与调控语法,提高基因功能预测的准确性。
现有的分词策略在DNA序列应用中存在哪些缺陷?
现有分词策略存在根本性缺陷,限制了模型的泛化能力,无法有效捕捉生物语法和功能元件的边界。
GenArt模型在下游任务中的表现如何?
GenArt在多个下游任务中表现优越,尤其在长序列任务上表现稳定,超越了其他模型。
如何验证GenArt模型捕获功能元件边界的能力?
通过对甲基化位点和多碱基功能元件的召回率进行评估,验证模型的边界捕获能力。
林琛教授的研究对基因组学有什么影响?
林琛教授的研究推动了基因组学从数据读取向功能理解的转变,为基因组研究提供了新思路。
