
播放器音频后处理实践(一)
内容提要
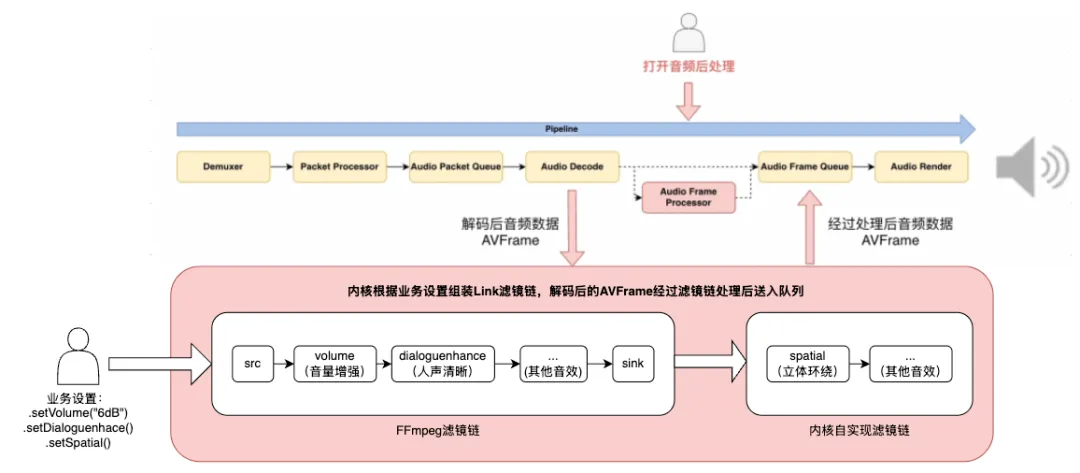
本文介绍了播放器音频后处理技术,重点在重低音和清晰人声的实现。通过FFmpeg音频滤镜框架,构建高效音效处理链,以提升音质和听感,适用于多种播放场景。
关键要点
-
音频后处理在现代播放器中是关键组件,提升听觉体验。
-
文章介绍基于FFmpeg的音频后处理技术,聚焦重低音和清晰人声。
-
重低音通过低通滤波器和动态增益控制增强低频表现。
-
清晰人声结合频段增强和背景音抑制技术提升对白清晰度。
-
音频后处理技术分为音质增强、效果添加和缺陷修正。
-
播放内核支持多种音效,包括音量增强、清晰人声和降噪。
-
重低音效果增强低频段声音,适用于音乐、电影和游戏。
-
移动设备在低频表现上受限于物理尺寸和功率输出。
-
EQ和谐波生成技术用于增强低频感知。
-
清晰人声处理包括识别说话者、减少背景噪音和频率调整。
-
dialoguenhance滤镜用于增强立体声对话,提供多种参数设置。
-
文章总结了重低音和清晰人声的实现逻辑和参数控制策略。
延伸解读
音频后处理的重要性
在现代播放器中,音频后处理不仅是提升音质的手段,更是用户体验的关键。通过定制化的音效增强,播放器能够在不同的播放场景中提供更具吸引力的听觉体验,尤其是在嘈杂环境中,清晰的人声处理显得尤为重要。
移动设备的物理限制
移动设备在低频表现上受到物理尺寸和功率输出的限制,导致低频效果往往不如大型音响系统。开发者在设计音频后处理方案时,需要考虑这些限制,采用合适的技术手段来优化低频表现,以提升用户的听感体验。
技术实现的复杂性
音频后处理技术涉及多个复杂的处理步骤,包括频段增强、背景音抑制和动态控制等。开发者在实现这些功能时,需要精确调节各类参数,以确保音质的提升不会引入失真或其他音质问题。
延伸问答
音频后处理技术的核心目标是什么?
音频后处理的核心目标是通过数字信号处理技术对原始音频进行音质增强、效果添加或缺陷修正。
如何通过FFmpeg实现重低音效果?
重低音效果通过构建低通滤波器和动态增益控制逻辑来增强低频段表现。
清晰人声的处理技术包括哪些步骤?
清晰人声的处理包括识别主要说话者、减少背景噪音、调整频率平衡和应用压缩与均衡。
移动设备在低频表现上有哪些限制?
移动设备的低频表现受限于扬声器尺寸小和功率输出低,导致低频声波产生不足。
FFmpeg中的dialoguenhance滤镜有什么功能?
dialoguenhance滤镜用于增强立体声对话,生成环绕声输出并强化语音内容。
音频后处理技术的分类有哪些?
音频后处理技术主要分为音质增强、效果添加和缺陷修正三类。
