
EP186:延迟与吞吐量
内容提要
若用户流程测试覆盖率低于80%,可能存在漏洞。QA Wolf的AI解决方案可在15分钟内高效提升测试覆盖率,减少手动测试和QA周期,显著提高测试效率。
关键要点
-
用户流程测试覆盖率低于80%时,可能存在漏洞。
-
QA Wolf的AI解决方案可在15分钟内提升测试覆盖率,减少手动测试和QA周期。
-
QA Wolf帮助Drata团队实现了4倍的测试用例和86%的QA周期加速。
-
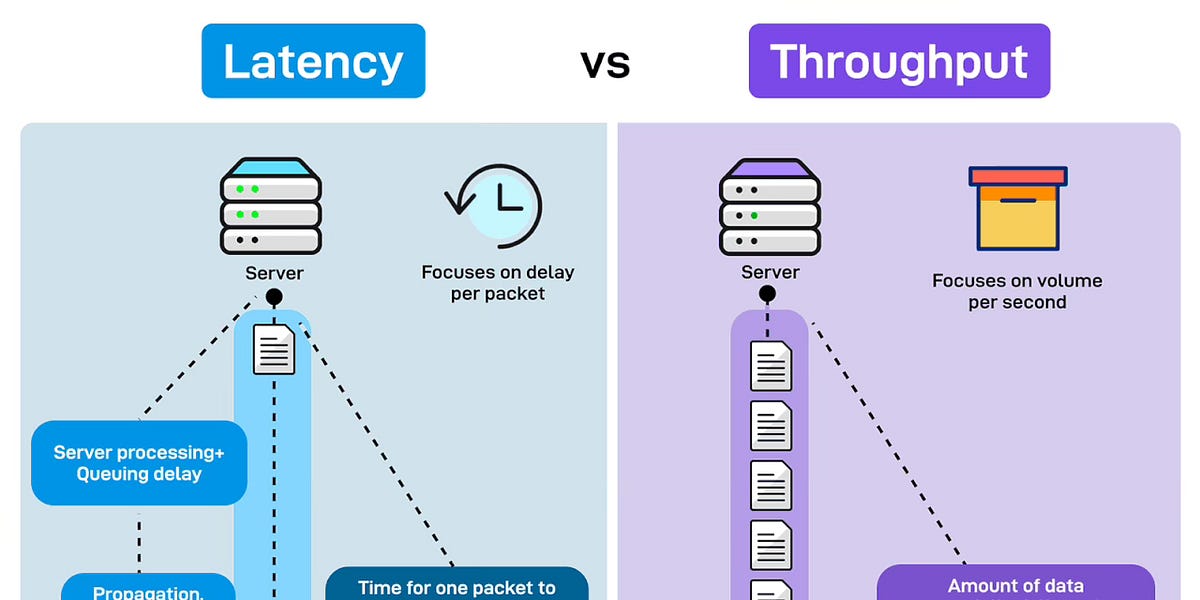
延迟和吞吐量是衡量应用性能的两个重要指标。
-
延迟是每个数据包的延迟,影响用户的响应感受。
-
吞吐量是单位时间内成功传输的数据量,反映系统的处理能力。
-
系统设计的20个重要概念包括负载均衡、缓存、数据库分片等。
-
调试慢API的步骤包括检查网络、后端代码、数据库和基础设施。
-
大型语言模型(LLMs)处理文本的过程包括预处理、标记化和映射到Token ID。
-
RAG和微调是适应大型语言模型的新任务的两种方法,分别侧重于实时知识获取和离线训练。
延伸解读
测试覆盖率的重要性
用户流程测试覆盖率低于80%时,软件中可能存在未发现的漏洞。这意味着在发布前,团队需要优先确保测试覆盖率,以降低潜在风险。QA Wolf的解决方案可以快速提升覆盖率,帮助团队在短时间内识别和修复问题,确保软件质量。
延迟与吞吐量的区别
延迟和吞吐量是评估应用性能的两个关键指标。延迟影响用户的响应体验,而吞吐量则反映系统处理请求的能力。理解这两者的区别有助于开发者优化应用性能,确保用户在使用过程中获得流畅的体验。
调试慢API的策略
当API响应缓慢时,开发者应采取系统化的方法进行调试。首先检查网络和后端代码,确保没有高延迟或复杂的业务逻辑导致性能问题。数据库索引和外部API的调用也需关注,以避免不必要的延迟。
延伸问答
如何提高用户流程测试的覆盖率?
可以使用QA Wolf的AI解决方案,在15分钟内高效提升测试覆盖率,减少手动测试和QA周期。
延迟和吞吐量有什么区别?
延迟是每个数据包的延迟,影响用户的响应感受;吞吐量是单位时间内成功传输的数据量,反映系统的处理能力。
QA Wolf的解决方案对团队有什么具体帮助?
QA Wolf帮助Drata团队实现了4倍的测试用例和86%的QA周期加速。
如何调试慢API?
调试慢API的步骤包括检查网络、后端代码、数据库和基础设施,确保逐步定位问题。
大型语言模型是如何处理文本的?
大型语言模型通过预处理、标记化和映射到Token ID的过程来处理文本。
RAG和微调有什么区别?
RAG在运行时从外部源获取知识,而微调是通过离线训练更新模型权重,使模型在特定领域成为专家。
