
什么是数据血统,为什么它很重要?
原文英文,约1300词,阅读约需5分钟。
📝
内容提要
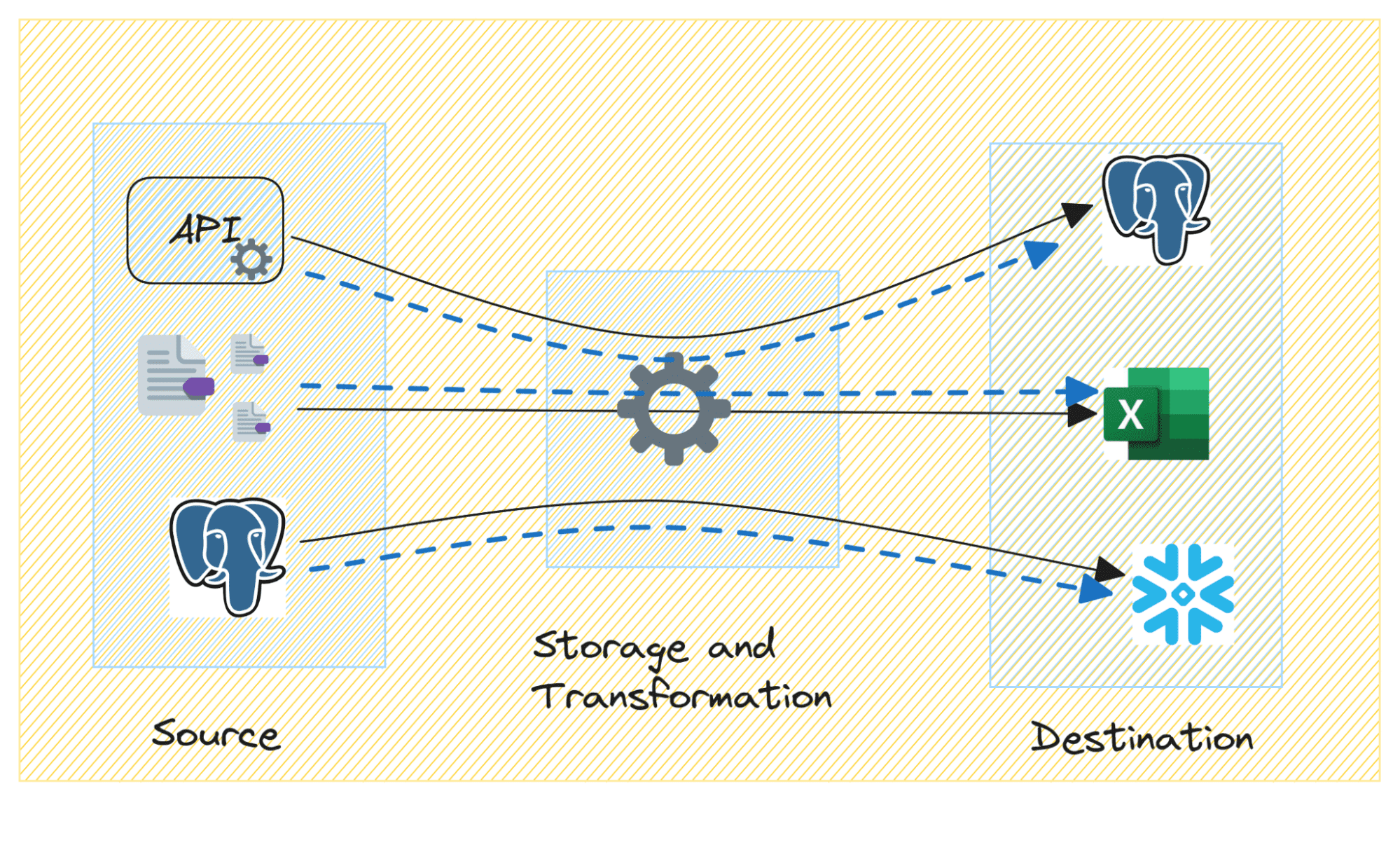
数据血统是追踪和可视化数据在数据管道或系统中流动和转换的过程。它提供了对数据的起源、移动和转换的详细了解,帮助组织提高数据质量、确保合规性等。数据血统的重要性在于维护数据质量、满足法规要求、故障排除、影响分析、管理风险、审计和治理、提高操作效率等方面。一些常用的数据血统工具包括Collibra、Informatica Axon、IBM InfoSphere Information Governance Catalog、Apache Atlas和Erwin Data Intelligence。
🎯
关键要点
-
数据血统是追踪和可视化数据在数据管道或系统中流动和转换的过程。
-
数据血统提供了对数据的起源、移动和转换的详细了解,帮助组织提高数据质量和确保合规性。
-
数据血统的关键组成部分包括源系统、元数据、数据移动和转换、以及最终目的地。
-
数据血统在维护数据质量和完整性方面至关重要,确保数据准确、可信并与业务目标一致。
-
数据血统帮助组织满足法规要求,提供数据移动、转换和存储的全面记录。
-
数据血统简化故障排除过程,帮助快速识别和解决数据问题。
-
数据血统在影响分析中提供清晰视图,帮助决策者评估数据源、结构或流程的变化对系统的影响。
-
数据血统是数据治理的基础工具,确保数据处理符合既定标准和合规要求。
-
通过可视化数据流,数据血统帮助识别冗余流程和瓶颈,优化数据管理的整体效率。
-
一些常用的数据血统工具包括Collibra、Informatica Axon、IBM InfoSphere Information Governance Catalog、Apache Atlas和Erwin Data Intelligence。
