
让 AI 也能当“反洗钱专家“——一个通俗易懂的模型训练故事
内容提要
本文介绍了如何通过培训AI模型Qwen-3 8B,使其成为反洗钱领域的专家。首先,准备法律法规、真实案例和国际组织文件作为教材,然后对问题进行难度分级,最后采用循序渐进的训练方法。结果表明,复杂问题的训练效果更佳,证明了循序渐进的学习方式对AI的有效性,该方法可推广至其他专业领域。
关键要点
-
本文介绍了如何通过培训AI模型Qwen-3 8B,使其成为反洗钱领域的专家。
-
准备教材包括法律法规、真实案例和国际组织文件,设计了3629道问题。
-
问题难度分级,采用聚类方法将问题分为42个组,并根据稀有度、独特性和长度打分。
-
训练采用循序渐进的方法,分为10个阶段,逐步增加问题难度。
-
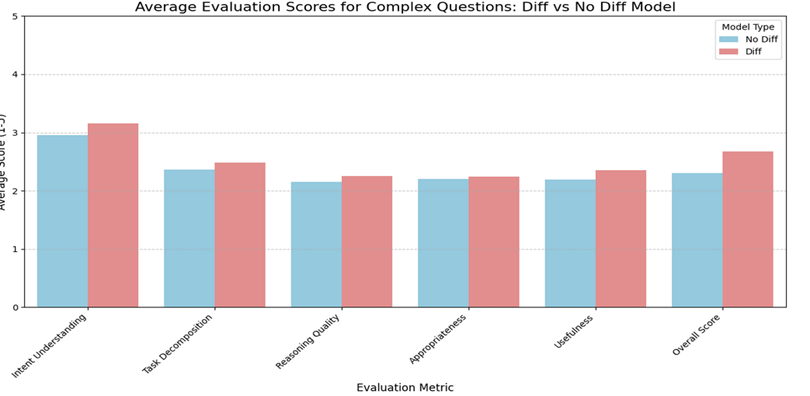
训练结果显示,循序渐进的训练方式对复杂问题的理解和推理能力更有效。
-
对于长文本问题,难度递增训练使模型更有耐心,逻辑更连贯。
-
处理常规问题时,简单粗暴的训练方式反而更有效。
-
总结认为,循序渐进的学习方式对AI有效,且该方法可推广至其他专业领域。
延伸解读
循序渐进的重要性
本文强调了循序渐进的训练方法在AI学习中的有效性。通过将问题难度分级,AI能够更好地理解复杂问题。这种方法不仅适用于反洗钱领域,还可以推广到医疗、法律等其他专业领域,帮助AI更扎实地掌握专业知识。
模型选择的考量
在选择AI模型时,需考虑任务的复杂性。如果任务涉及深度推理,推荐使用diff模型;而对于基础问答,no_diff模型则足够。这种选择能够提高效率,确保AI在特定任务中的表现最佳。
训练方法的局限性
尽管循序渐进的训练方法效果显著,但在追求复杂推理能力的同时,基础能力可能会有所下降。因此,在设计训练方案时,需平衡深度与广度,确保AI在各方面能力的均衡发展。
延伸问答
如何通过培训AI模型使其成为反洗钱专家?
通过准备法律法规、真实案例和国际组织文件作为教材,并采用循序渐进的训练方法。
在培训过程中,如何设计问题的难度?
通过聚类方法将问题分为42个组,并根据稀有度、独特性和长度打分,形成难度分数。
循序渐进的训练方法有什么优势?
这种方法对复杂问题的理解和推理能力更有效,能提高模型的逻辑连贯性和耐心。
训练AI模型时,如何评估其效果?
通过设计复杂意图测试、长上下文测试和常规测试,检验模型的理解和推理能力。
对于长文本问题,哪种训练方式更有效?
难度递增的训练方式使模型在处理长文本时更有耐心,逻辑更连贯。
这套培训方法可以应用于哪些其他领域?
该方法可推广至医疗、法律等其他专业领域。
