
通用语义层对您的数据堆栈有益的6个原因
原文英文,约500词,阅读约需2分钟。
📝
内容提要
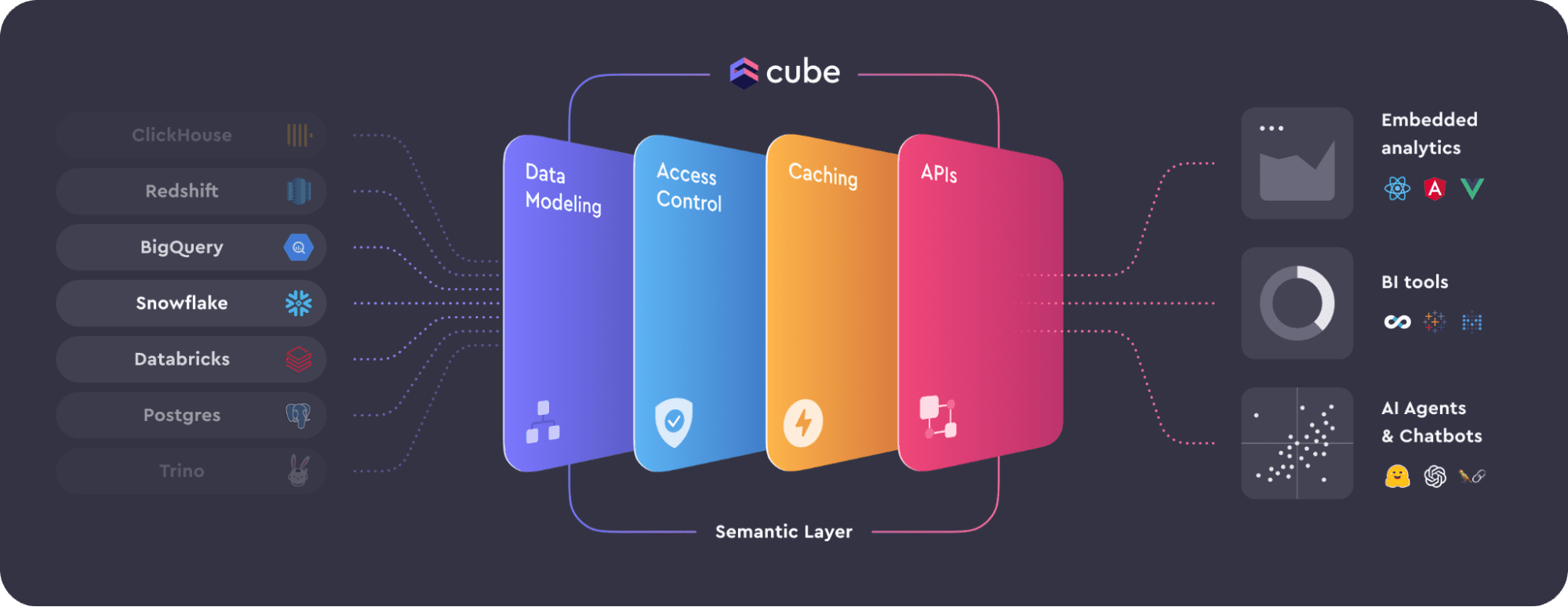
语义层在数据堆栈中的作用和优势,连接数据源和分析工具,提供有意义的数据给用户。包含业务规则、数据定义和元数据,标准化报告工具和数据源之间的词汇。关键层次有数据建模、数据访问控制、缓存和API。好处包括数据一致性、数据安全、数据性能、堆栈灵活性、快速上市、未来可扩展性。应用包括嵌入式分析、商业智能和人工智能。
🎯
关键要点
-
语义层在数据堆栈中充当数据源和分析工具之间的桥梁,简化现代数据环境的复杂性。
-
语义层作为上下文过滤器,抽象原始数据并以有意义的方式呈现给最终用户。
-
语义层包含预定义的业务规则、数据定义和元数据,标准化报告工具和数据源之间的词汇。
-
语义层的四个关键层次包括数据建模、数据访问控制、缓存和API。
-
数据建模确保在一个位置提供一致的见解和指标,数据访问控制管理授权用户的数据访问。
-
缓存优化性能,通过存储数据减少冗余查询,提升响应速度。
-
API确保不同数据源和下游应用程序之间的兼容性。
-
语义层确保数据一致性,促进无缝集成和高效分析。
-
集中控制数据访问降低了安全风险,确保遵守数据隐私法规。
-
缓存层优化响应时间,对实时处理和人工智能应用至关重要。
-
语义层提供堆栈灵活性,使工具选择不影响创新。
-
语义层缩短开发者创建或维护数据应用和数据模型的时间。
-
语义层适应不断变化的业务需求和新数据源,确保长期灵活性和智能。
-
嵌入式分析加速应用开发,从几个月缩短到几天。
-
语义层简化数据编排,节省数据工程师的时间,确保BI工具之间的一致性见解和指标。
-
语义层促进专有数据与人工智能的轻松集成,简化复杂的连接,提升查询响应时间。
-
Cube在GigaOm Sonar报告中被评为领导者和快速移动者,强调其强大的代码优先导向和原生API支持。
🏷️
