
stable_diffusion学习
原文中文,约5300字,阅读约需13分钟。
📝
内容提要
本文介绍了稳定扩散模型的结构和流程,通过在低维潜在空间上应用扩散过程来降低内存和计算复杂性。该模型包括自动编码器、U-Net和文本编码器等模块,通过噪声调度算法进行去噪过程。文章还提供了代码实现。
🎯
关键要点
-
稳定扩散模型的前身是潜在扩散模型,旨在降低内存和计算复杂性。
-
扩散模型在生成图像数据方面表现出色,但反向去噪过程较慢且内存消耗大。
-
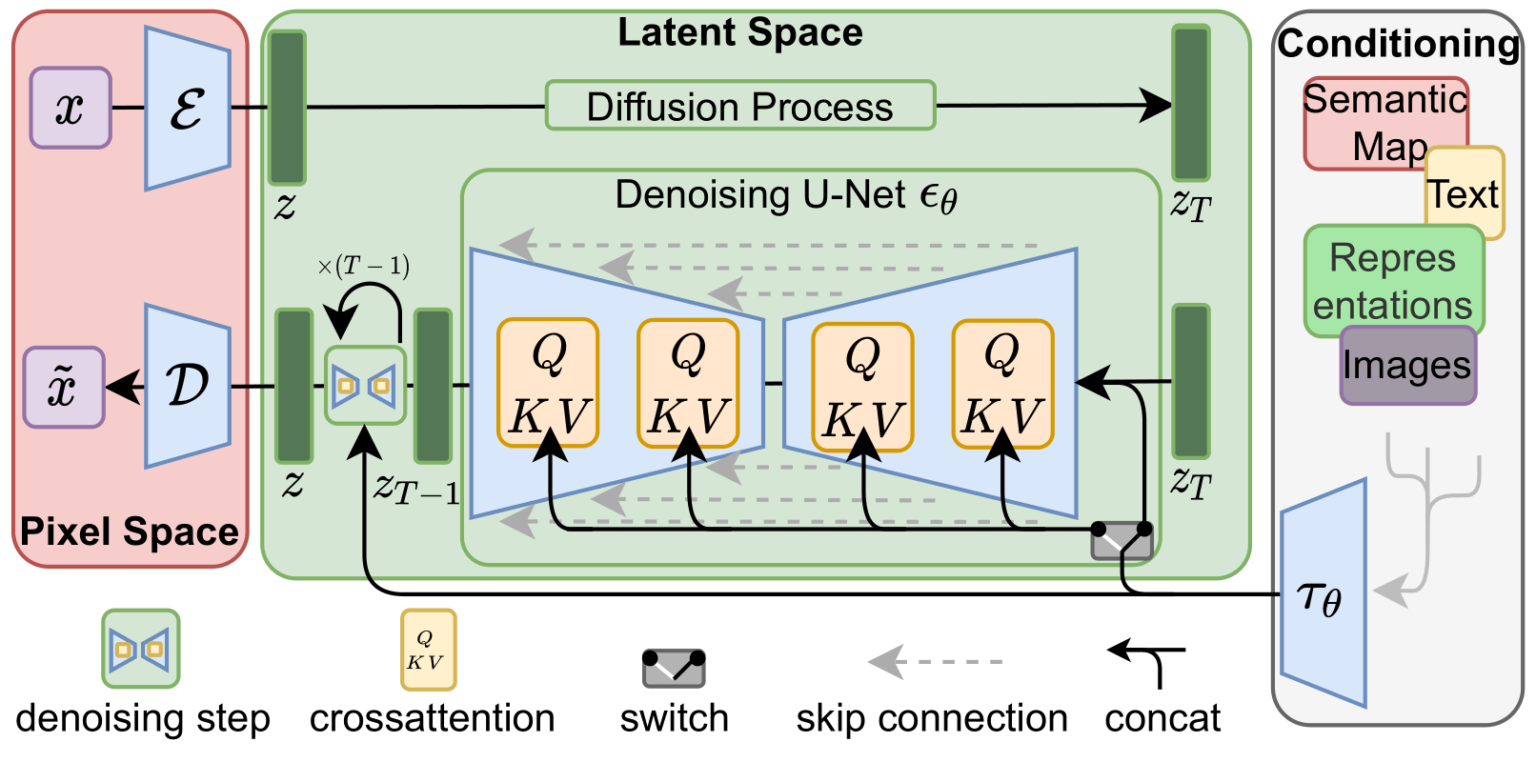
潜在扩散通过在低维潜在空间上应用扩散过程来解决这些问题。
-
潜在扩散模型包含自动编码器、U-Net和文本编码器等模块。
-
VAE模型由编码器和解码器组成,编码器将图像转换为低维潜在表示。
-
U-Net具有编码器和解码器部分,使用ResNet块进行图像表示的压缩和解压。
-
U-Net通过跨注意力层将输出条件设置在文本嵌入上。
-
文本编码器将输入提示转换为U-Net可以理解的嵌入空间,通常使用CLIP的文本编码器。
-
扩散过程通过随机噪声生成图像,模型训练以处理这些噪声。
-
去噪过程需要特定的噪声调度算法来定义推理步骤和计算去噪图像。
-
在推理过程中,使用VAE解码器将潜在表示转换回图像。
🏷️
