
全面的 TableBench 数据集推动表格问答的发展
原文英文,约900词,阅读约需4分钟。
📝
内容提要
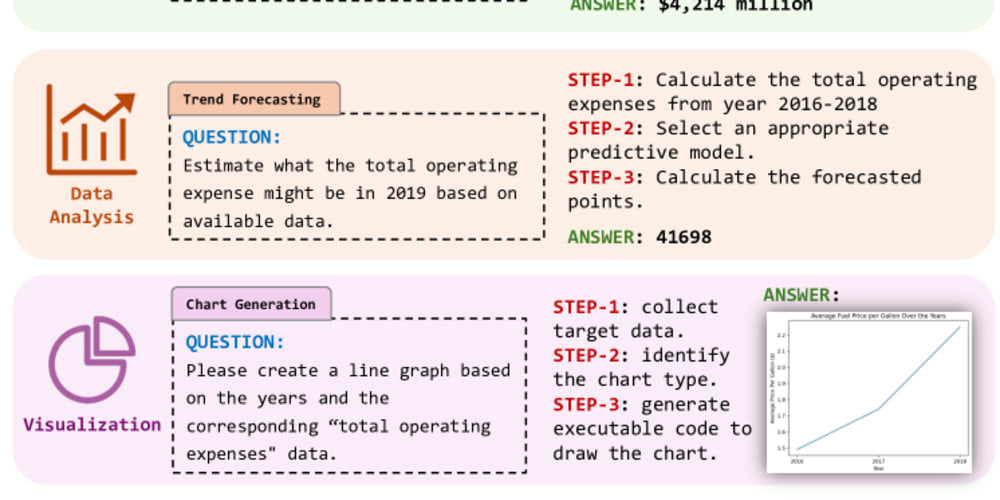
TableBench是一个全面且复杂的基准,用于评估表格问答系统。数据集包含各种类型的表格、问题和推理技巧,旨在推动表格问答领域的发展。该数据集包含超过100,000个表格-问题对,是该领域最大且最全面的基准之一。
🎯
关键要点
-
TableBench是一个全面且复杂的基准,用于评估表格问答系统。
-
数据集涵盖各种类型的表格、问题和推理技巧,旨在推动表格问答领域的发展。
-
TableBench数据集设计用于测试机器学习模型回答表格问题的能力。
-
数据集包含超过100,000个表格-问题对,是该领域最大且最全面的基准之一。
-
研究者通过多步骤过程确保数据集的质量和多样性,包括自动和手动技术生成表格和问题。
-
TableBench数据集的多样性和复杂性是其主要优势,能够处理复杂和多样的数据。
-
数据集的局限性包括表格主要是静态的,可能无法反映现实世界数据的动态性。
-
数据集主要集中在英语表格和问题,可能在其他语言或文化背景下的适用性有限。
-
存在潜在的偏见问题,机器学习模型可能会放大数据中的偏见。
-
TableBench数据集代表了表格问答领域的重要进展,可能成为研究者和从业者的重要资源。
❓
延伸问答
TableBench数据集的主要目的是什么?
TableBench数据集旨在评估表格问答系统的能力,推动该领域的发展。
TableBench数据集包含多少个表格-问题对?
TableBench数据集包含超过100,000个表格-问题对。
TableBench数据集的多样性和复杂性有什么优势?
其多样性和复杂性使其能够处理复杂和多样的数据,推动表格问答系统的能力。
TableBench数据集的局限性有哪些?
局限性包括表格主要是静态的,可能无法反映现实世界数据的动态性,以及主要集中在英语表格和问题上。
TableBench数据集是如何确保质量和多样性的?
研究者通过自动和手动技术生成表格和问题,并进行多步骤的过滤和验证来确保质量和多样性。
TableBench数据集对机器学习模型的影响是什么?
该数据集可能推动机器学习模型在表格问答领域的进步,帮助模型更好地理解和推理表格信息。
🏷️
