
超越向量存储:构建AI应用的完整数据层
内容提要
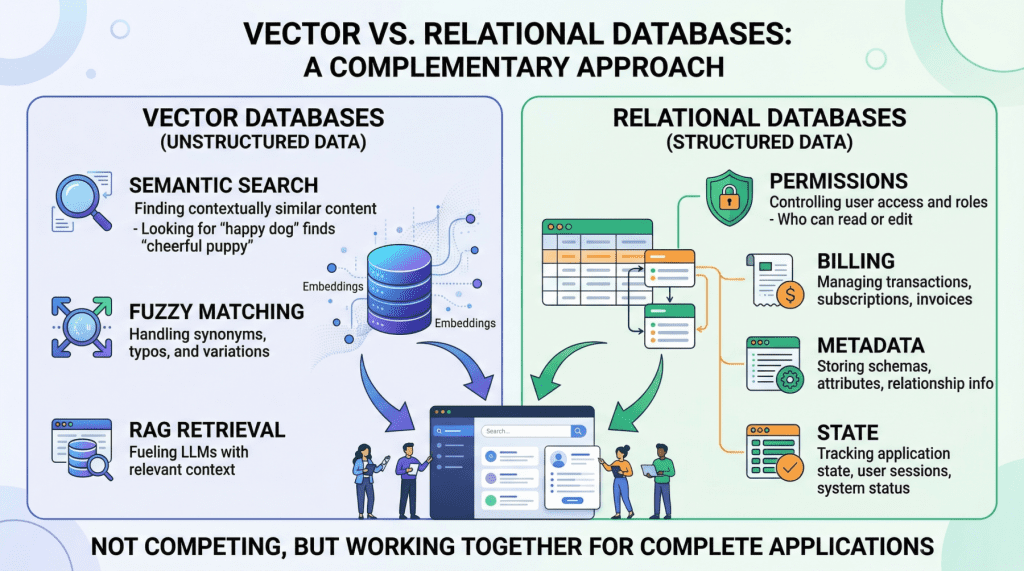
生产AI应用需要结合向量数据库和关系数据库。向量数据库擅长语义检索,但在结构化数据和事务处理上有限制。关系数据库则负责管理用户权限、元数据和账单等关键功能。混合架构能够有效整合两者,确保AI系统的可靠性和效率。
关键要点
-
生产AI应用需要结合向量数据库和关系数据库。
-
向量数据库擅长语义检索,但在结构化数据和事务处理上有限制。
-
关系数据库负责管理用户权限、元数据和账单等关键功能。
-
混合架构能够有效整合两者,确保AI系统的可靠性和效率。
-
向量数据库通过高维嵌入进行快速语义搜索,适合处理非结构化数据。
-
关系数据库提供确定性查询和严格的ACID保证,适合处理结构化数据。
-
在AI应用中,向量数据库和关系数据库应作为互补层共同工作。
-
使用pgvector可以将向量存储与结构化数据结合,简化操作复杂性。
延伸解读
向量数据库与关系数据库的互补性
在构建AI应用时,向量数据库和关系数据库各自发挥着独特的作用。向量数据库擅长语义检索,适合处理非结构化数据,而关系数据库则负责管理用户权限和结构化数据。两者的结合能够提升系统的可靠性和效率,确保在处理复杂事务时不出现数据错误。
混合架构的优势
采用混合架构可以有效整合向量数据库和关系数据库的优点。例如,使用pgvector可以将向量存储与结构化数据结合,简化操作复杂性。这种方法不仅提高了查询效率,还减少了系统维护的复杂度,适合中小规模的AI应用。
注意数据安全与权限管理
在AI应用中,确保数据安全和权限管理至关重要。关系数据库提供了精确的用户身份验证和访问控制,避免了数据泄露的风险。开发者在设计系统时,必须重视这一点,以确保用户只能访问其有权限查看的数据。
延伸问答
为什么生产AI应用需要同时使用向量数据库和关系数据库?
生产AI应用需要向量数据库进行语义检索,而关系数据库则负责管理结构化数据和事务处理,确保系统的可靠性和效率。
向量数据库的优势和局限性是什么?
向量数据库擅长快速语义搜索和处理非结构化数据,但在结构化数据和事务处理上存在局限性,无法保证查询的准确性。
关系数据库在AI应用中扮演什么角色?
关系数据库管理用户权限、元数据和账单等关键功能,提供确定性查询和严格的ACID保证,确保数据的准确性和一致性。
混合架构如何整合向量数据库和关系数据库?
混合架构将向量数据库用于语义检索,关系数据库处理其他事务,通过预过滤和后处理模式实现两者的有效协作。
pgvector在数据存储中有什么优势?
pgvector允许将向量存储与结构化数据结合,简化操作复杂性,适合中小规模的应用,避免了使用两个独立数据库的复杂性。
在AI应用中,如何确保数据安全和权限管理?
通过关系数据库进行用户身份验证和基于角色的访问控制,确保只有授权用户可以访问特定数据,防止数据泄露。
