
机器视觉压缩的三种途径:VCM、FCM 和 V-Nova 通配符
内容提要
视频编码技术正向机器视觉优化发展,主要有三种方案:面向机器的视频编码(VCM)、面向机器的特征编码(FCM)和V-Nova的LCEVC。VCM优化像素处理以支持机器任务,FCM直接传输神经网络特征,LCEVC结合低分辨率基础层与高分辨率增强层,兼顾机器分析与人工视觉需求。
关键要点
-
视频内容越来越多地用于机器分析,应用场景包括监控、自动驾驶、工业检测等。
-
传统编解码标准如H.264和HEVC以人类视觉为优化目标,限制了机器视觉任务的发展。
-
面向机器的视频编码(VCM)正在成为国际标准,优化目标转向机器视觉任务,保留对计算机视觉模型有用的信息。
-
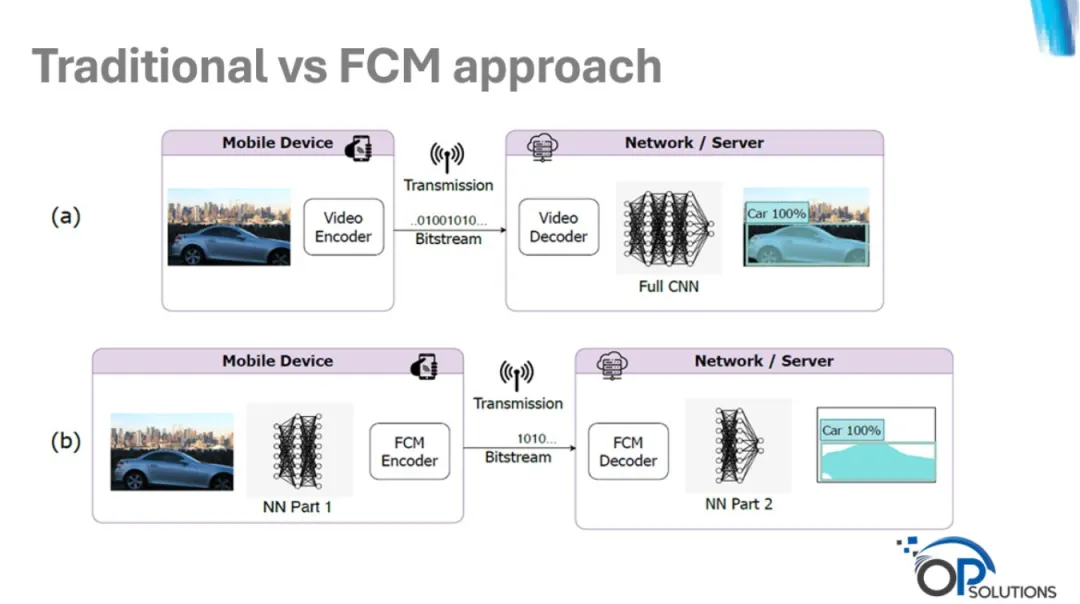
面向机器的特征编码(FCM)直接传输神经网络提取的特征,省去像素解码步骤,提高传输效率。
-
V-Nova的LCEVC采用分层结构,基础层为低分辨率视频,增强层补充细节,兼顾机器分析与人工视觉需求。
-
LCEVC的双层架构使其在机器视觉与人工视觉之间提供了实用的桥梁方案。
-
FCM在码率压缩效率上优于VCM,但要求通信两端均需兼容的AI模型。
-
市场选择哪种方案仍未确定,取决于具体的工作流需求和现有基础设施的兼容性。
延伸解读
机器视觉的应用场景
随着视频内容在监控、自动驾驶和工业检测等领域的广泛应用,机器视觉的需求日益增加。传统的视频编码标准如H.264和HEVC并未针对机器视觉进行优化,这为新型编码方案的出现提供了契机。了解这些应用场景有助于把握未来技术发展的方向。
FCM与VCM的比较
面向机器的特征编码(FCM)在码率压缩效率上优于面向机器的视频编码(VCM),但FCM要求通信双方必须兼容AI模型,限制了其应用场景。相比之下,VCM虽然在压缩效率上稍逊,但其兼容性更强,适合与现有视频基础设施无缝对接。
LCEVC的双重优势
V-Nova的LCEVC采用分层编码结构,既能满足机器分析的低分辨率需求,又能为人工视觉提供完整的高分辨率视频。这种设计使得LCEVC在实际应用中具备灵活性,能够同时服务于不同的用户需求,适合多种工作流场景。
延伸问答
机器视觉压缩的主要方案有哪些?
主要方案包括面向机器的视频编码(VCM)、面向机器的特征编码(FCM)和V-Nova的LCEVC。
VCM与传统视频编码的区别是什么?
VCM优化目标转向机器视觉任务,保留对计算机视觉模型有用的信息,而传统编码如H.264和HEVC以人类视觉为优化目标。
FCM的工作原理是什么?
FCM直接传输由神经网络提取的特征,省去像素解码步骤,提高传输效率,专为机器处理设计。
LCEVC的架构设计有什么特点?
LCEVC采用分层结构,基础层为低分辨率视频,增强层补充细节,兼顾机器分析与人工视觉需求。
FCM在码率压缩效率上有什么优势?
FCM在码率压缩效率上优于VCM,能够实现高达90%的码率压缩,同时保持目标检测精度。
市场上选择哪种机器视觉压缩方案的因素是什么?
市场选择方案取决于具体的工作流需求和现有基础设施的兼容性。
