像素化!设计系统中视觉一致性的网络简易指南
Blog Awesome
·

AI论文评审:自一致性提升语言模型中的链式思维推理
freeCodeCamp.org
·

一致性,但追求卓越而非外观
Jim Nielsen’s Blog
·

评估企业级智能体:从原型验证到生产就绪
亚马逊AWS官方博客
·

在混合操作系统环境下实现跨平台统一通信的一致性
实时互动网
·

在AI/BI中设计美观的仪表板
Databricks
·
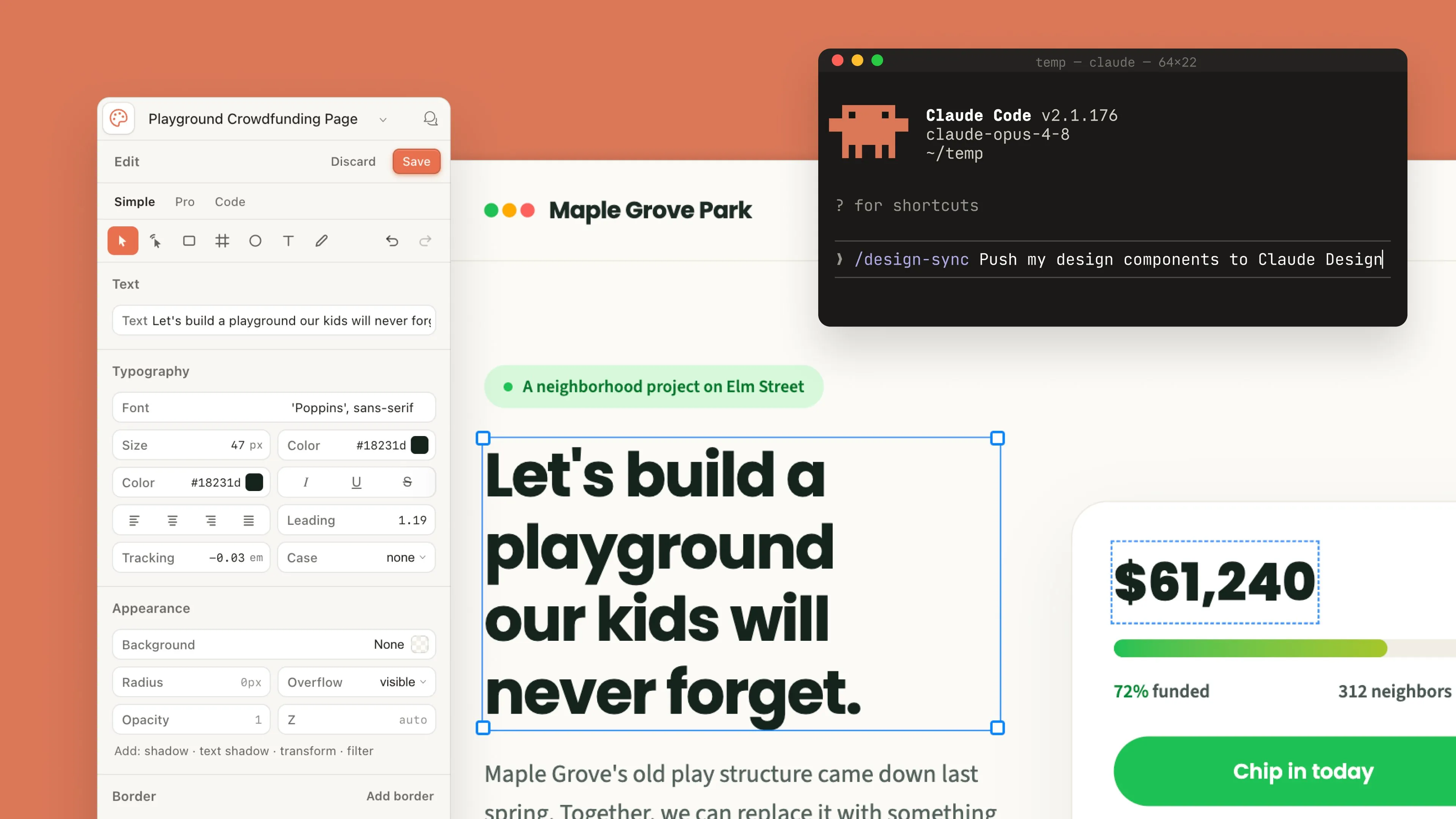
Claude Design 现已在日常工作中保持品牌一致性
Claude
·

组复制与Percona XtraDB集群:一致性的真实成本
Percona Database Performance Blog
·