

一分钟读论文:《MCPEvol-Bench:MCP服务器动态演化的LLM Agent性能基准测试》
Micropaper
·

在Databricks的数百万行代码库上对编码代理进行基准测试
Databricks
·

GitHub Copilot如何实现GitHub Pages的零DNS配置
The GitHub Blog
·
在编码评估中区分信号与噪声
OpenAI
·

介绍Kotlin基准测试以评估AI编码代理
The JetBrains Blog
·
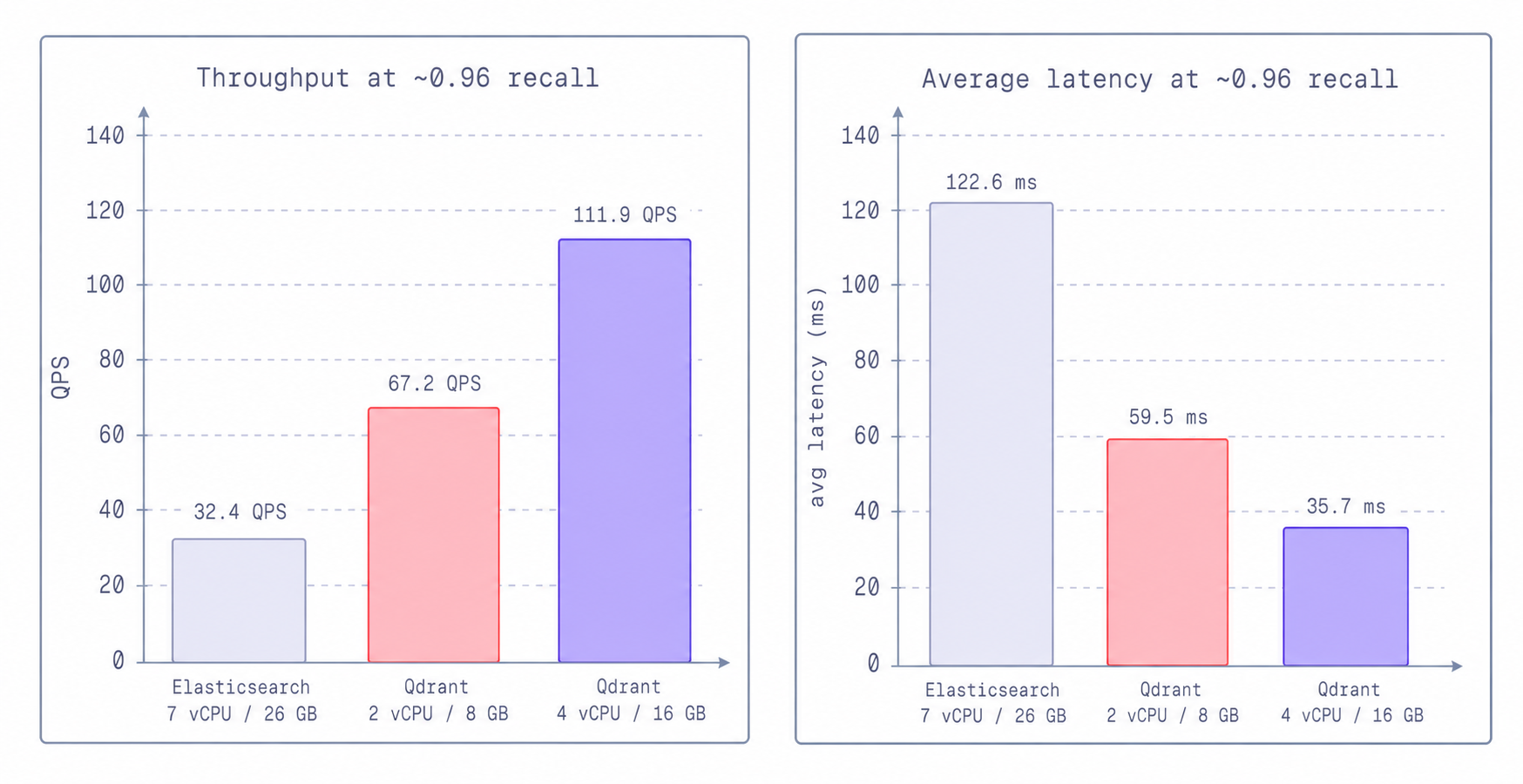
Qdrant在吞吐量上提高了2倍,延迟降低了50%,计算资源减少到1/3,超越了Elastic的DiskBBQ
Qdrant - Vector Database
·

一分钟读论文:《AgentGym2——从理想化基准到真实世界部署的评估范式转移》
Micropaper
·

基准测试的意义差距
The JetBrains Blog
·
Anthropic的Claude Sonnet 5系统卡比其基准测试更能揭示AI的未来
The New Stack
·

AI 范式雷达:《Agent规划脆弱性——检索受限下大规模工具生态中的长期规划基准测试》
Micropaper
·

一分钟读论文:《当工具失败时:LLM智能体的动态重规划与异常恢复基准测试》
Micropaper
·

在博弈论中,通才有时胜过专家
MIT News - Artificial intelligence
·

LivePerson如何通过基准测试优化GCP上的Logstash和Kafka性能
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

Java微服务能否与Go一样快速?2026年基准测试更新
insidejava
·

AI 范式雷达:《Agent安全新范式:从静态对齐到动态诊断护栏》
Micropaper
·

NVIDIA Blackwell在首个代理AI基础设施基准测试中领先
NVIDIA Blog
·
