


如何在Python和LangGraph中构建您的第一个多智能体AI系统
freeCodeCamp.org
·
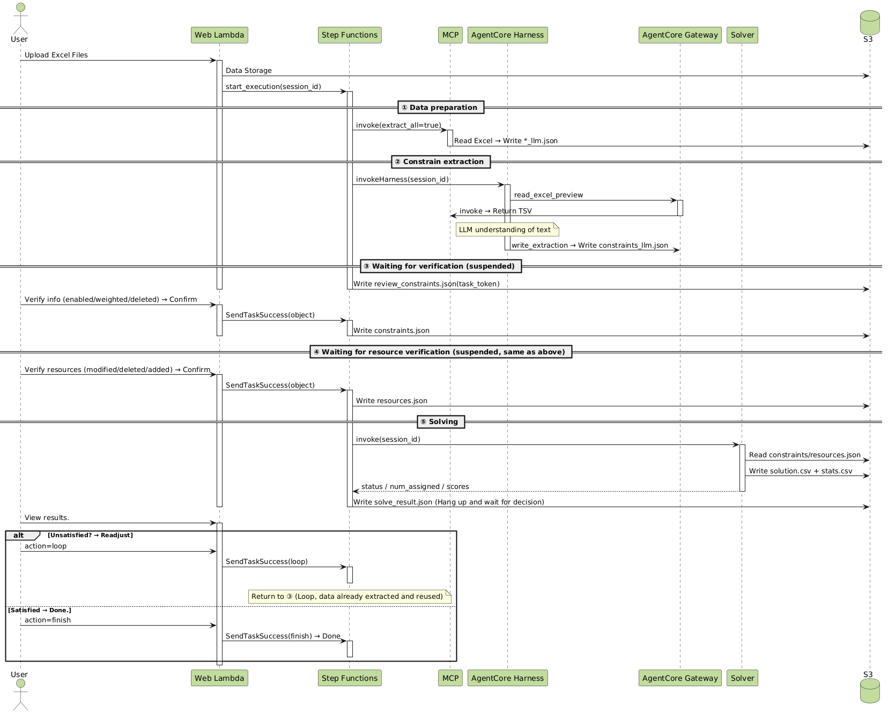
基于AgentCore harness构建高效、稳定的行程分配与优化多智能体系统
亚马逊AWS官方博客
·

多智能体团队限制专家发挥
Apple Machine Learning Research
·


AI 范式雷达:《OrchRM——多智能体编排的自监督奖励建模新范式》
Micropaper
·


一分钟读论文:《思想的经济:Agent经济交互中的多智能体智能涌现》
Micropaper
·

一分钟读论文:《像团队一样进化:基于大语言模型的多智能体系统协作自我进化》
Micropaper
·
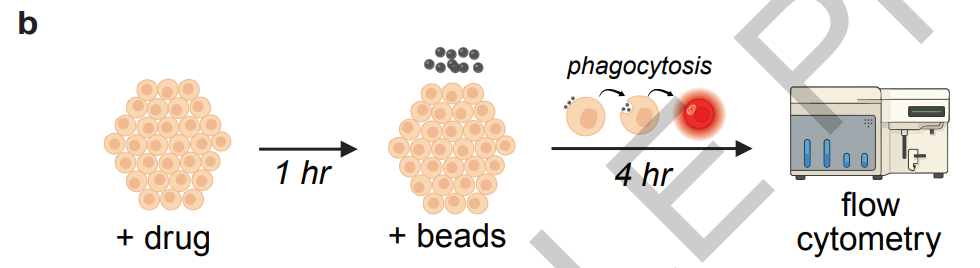
30分钟整合550篇文献,生物学多智能体Robin跑通自主科研闭环,挖掘dAMD候选疗法
HyperAI超神经
·

如何在Python中构建多智能体研究助手
MachineLearningMastery.com
·

