

Kubernetes上的大型语言模型(LLM)第一部分:理解威胁模型
Cloud Native Computing Foundation
·

Athena:用于与大型语言模型(LLM)协作生成应用的中间表示
Apple Machine Learning Research
·

超越提示工程:5种实用技术检测和缓解大型语言模型的幻觉
MachineLearningMastery.com
·
基于词汇训练,基于概念校准:大型语言模型中的语义校准的出现
Apple Machine Learning Research
·

识别过度自信的大型语言模型的更好方法
MIT News - Artificial intelligence
·
/filters:no_upscale()/news/2026/03/google-bayesian-llm/en/resources/1b2-1773346187597.jpg)


Runpod报告:Qwen已超越Meta的Llama,成为最广泛部署的自托管大型语言模型
The New Stack
·

12小时掌握大型语言模型的微调技巧
freeCodeCamp.org
·
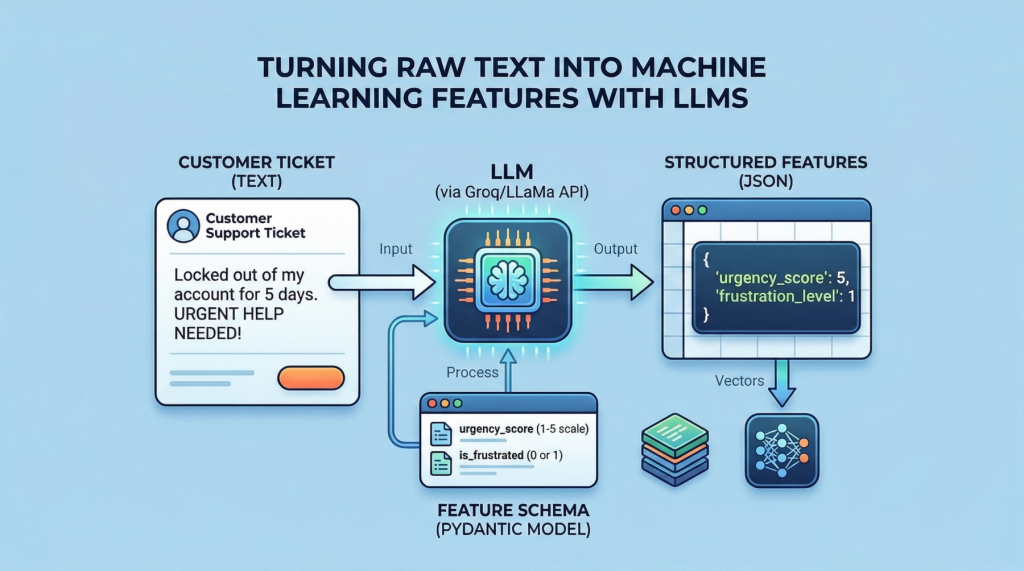
从文本到表格:利用大型语言模型进行表格数据的特征工程
MachineLearningMastery.com
·

连芯片制造商也在开发大型语言模型
Stack Overflow Blog
·

什么是提示缓存?大型语言模型的速度与成本指南
Redis Blog
·
上下文衰退如何影响企业AI和大型语言模型(LLM)的结果,以及如何解决这一问题
The New Stack
·

Junie CLI:支持多种大型语言模型的编码助手现已进入Beta阶段
The JetBrains Blog
·
/filters:no_upscale()/sponsorship/topic/08e8377f-e75b-4cb2-9c90-3e4f8149a830/HarnessWebinarApr16-RSB-1772813583373.png)

如何通过使用Ollama在本地运行大型语言模型来保护敏感数据
freeCodeCamp.org
·

大型语言模型、乐高和LED灯:一位Elastic工程师如何保持活力并以好奇心引领
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·
