

别让AI搜不到你:聊聊大语言模型优化(LLMO)
人言兑
·


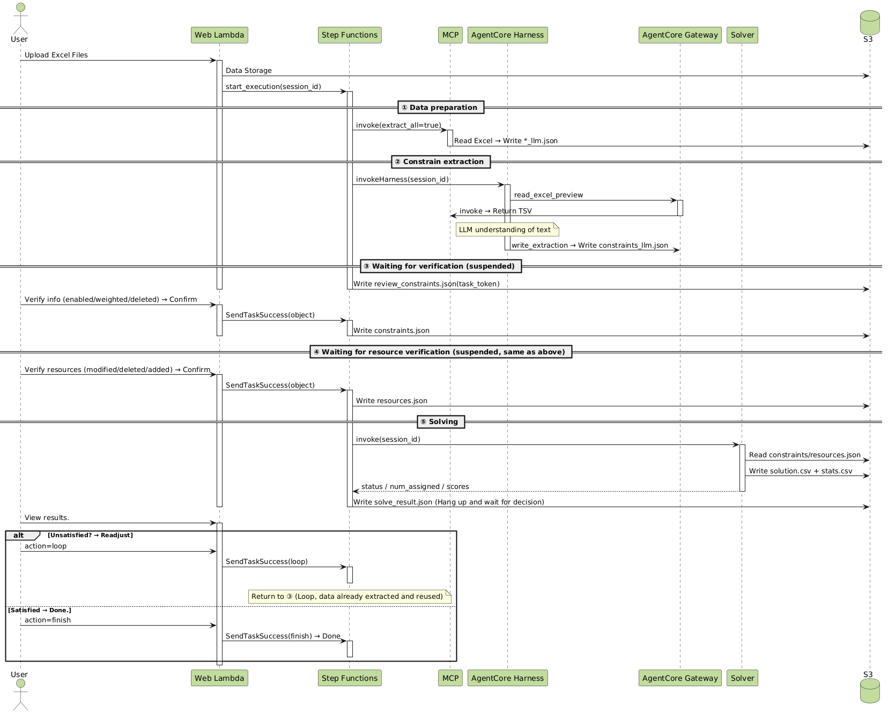
基于AgentCore harness构建高效、稳定的行程分配与优化多智能体系统
亚马逊AWS官方博客
·
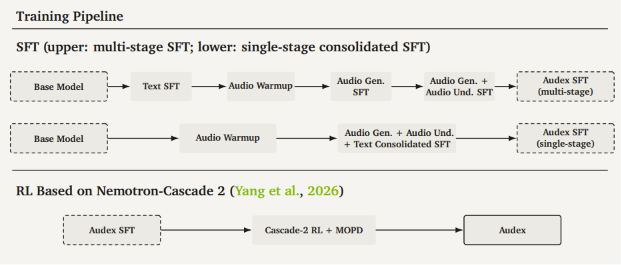

Claude Code 焚诀(一):六种心智模型 - cxuanAI
程序员cxuan
·
别争了!香农老婆,才是世界上第一个大语言模型
量子位
·


什么是会话式 AI?聊天机器人的核心技术拆解
实时互动网
·

AI 聊天机器人与传统客服机器人有什么区别?
实时互动网
·
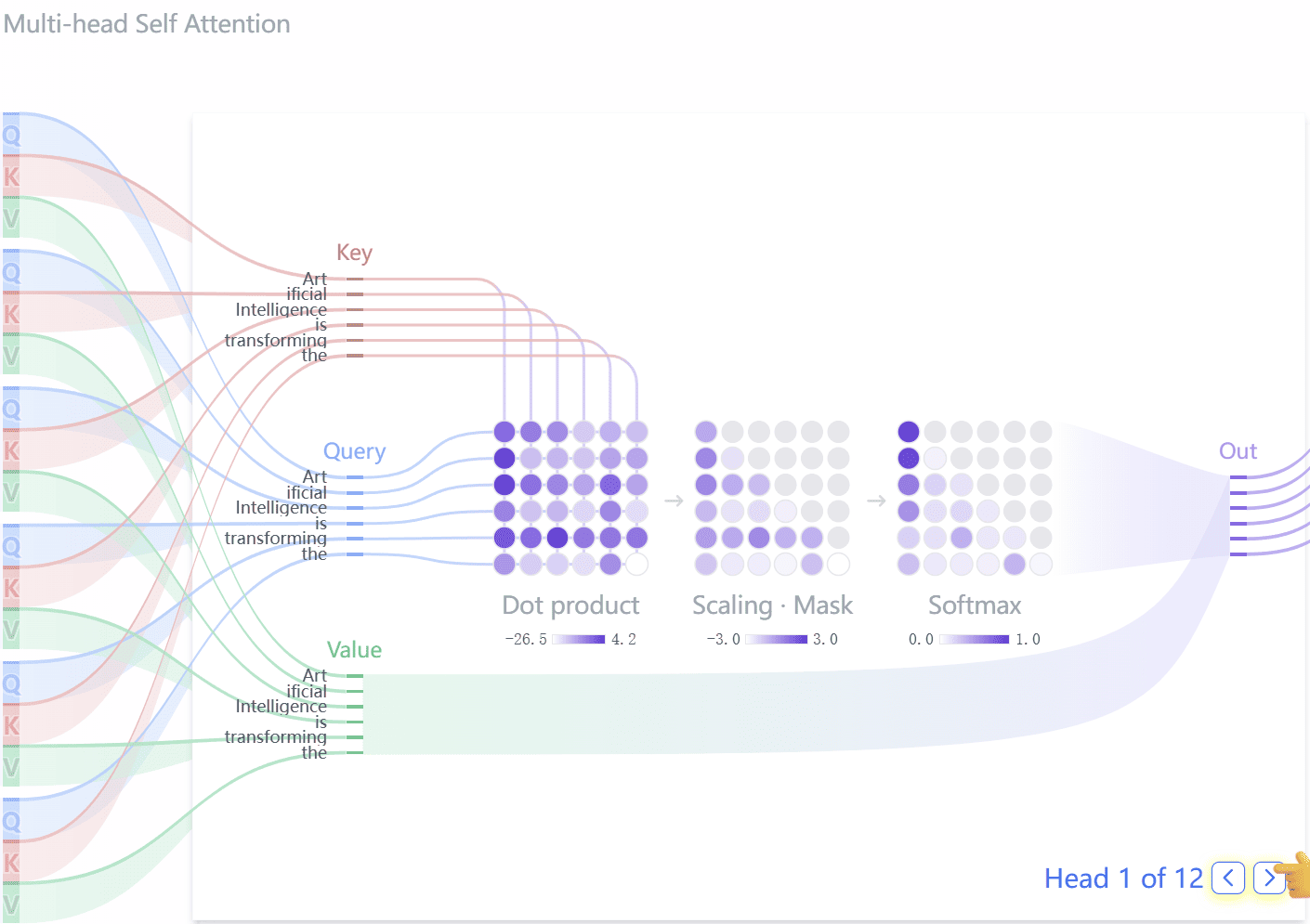
从简单助手到强生产力,香港大学黄超团队的AI Agent落地攻坚实录
HyperAI超神经
·
