产品实验与提升建模:将您的LLM功能推出目标定位于真正受益的用户(Python实现)
freeCodeCamp.org
·

重新构想湖屋上的数据建模:介绍Vibe数据建模
Databricks
·
更好的金属合金行为建模方法
MIT News - Artificial intelligence
·

AI 范式雷达:《OrchRM——多智能体编排的自监督奖励建模新范式》
Micropaper
·

语义层与上下文层:商业智能建模的终点与人工智能基础的起点
Redis Blog
·

STARFlow-V:基于归一化流的端到端视频生成建模
Apple Machine Learning Research
·

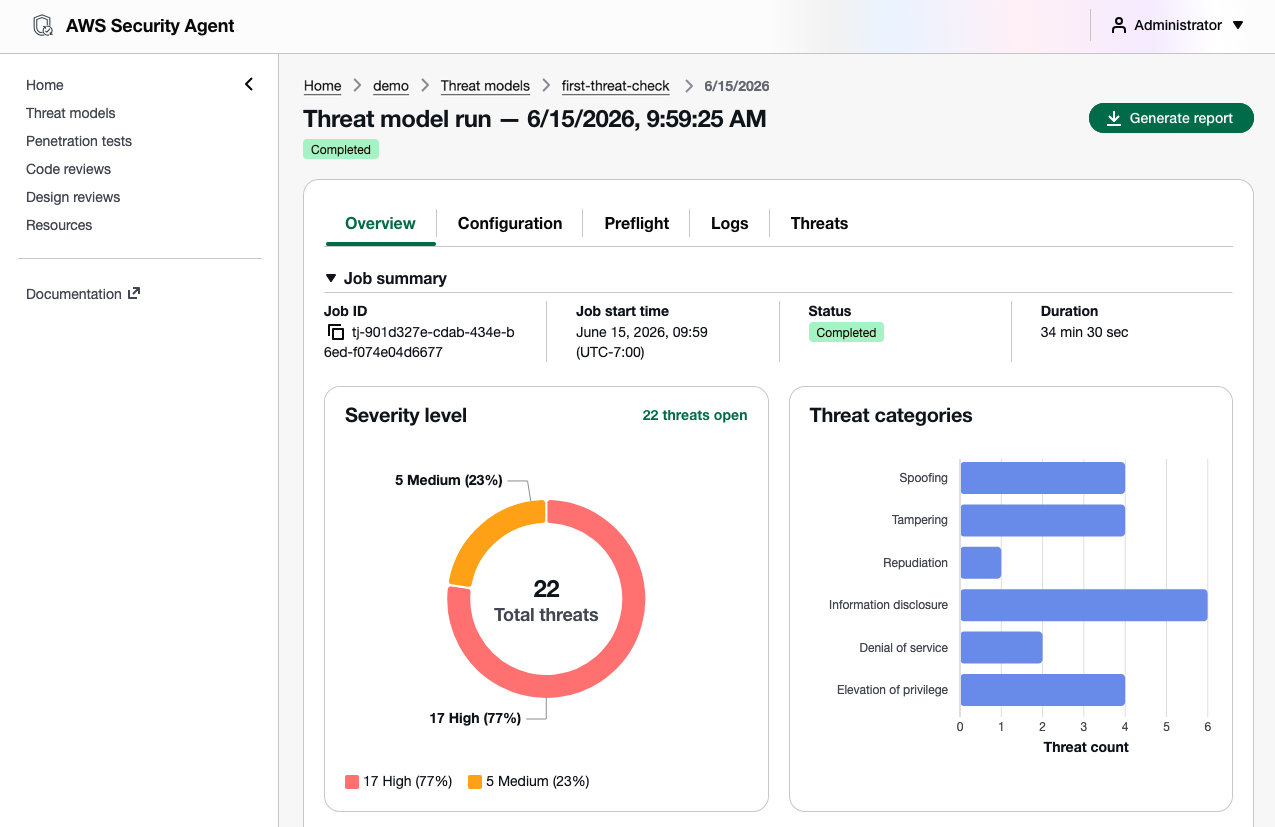
如何在安全软件开发中应用STRIDE威胁建模和SonarQube分析
freeCodeCamp.org
·