

一分钟读论文:《Qwen-AgentWorld:通用智能体的语言世界模型》
Micropaper
·

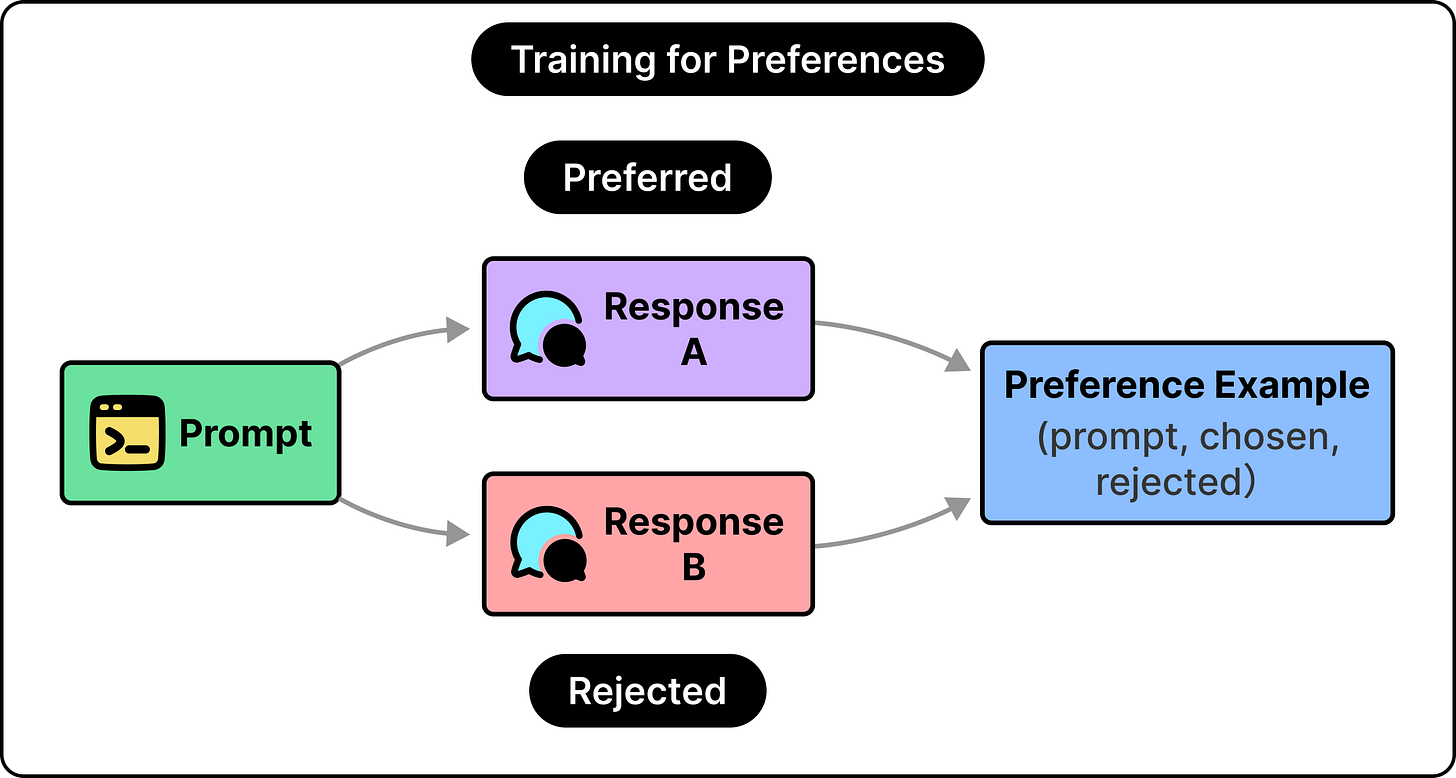
大型语言模型如何学习提供帮助(RLHF与DPO)
ByteByteGo Newsletter
·

行业领先的毫米级VLA强化学习方案Robo-ValueRL发布
全球TMT-美通国际
·

一分钟读论文:《CompactionRL——将上下文压缩引入强化学习》
Micropaper
·

Weblica:可扩展和可重复的视觉网络代理训练环境
Apple Machine Learning Research
·
MT-EditFlow:基于流匹配的多轮图像编辑强化学习
Apple Machine Learning Research
·

开放模型如何推动人工智能研究
NVIDIA Blog
·
关于强化学习微调视觉语言模型的鲁棒性与思维连贯性
Apple Machine Learning Research
·
通过可控轨迹学习结构化推理
Apple Machine Learning Research
·
学习扩散语言模型的解码策略
Apple Machine Learning Research
·
