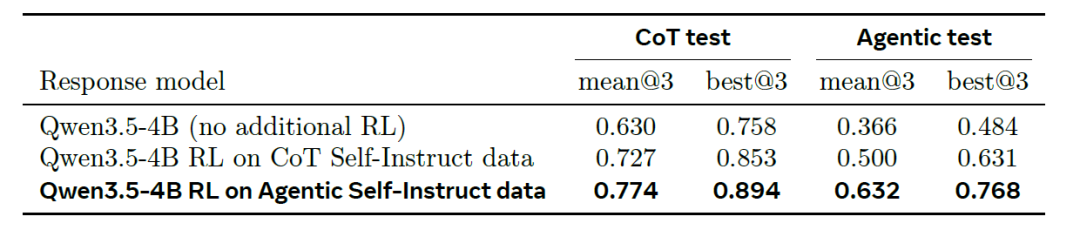
Meta提出AI数据科学家,Autodata构建高质量训练/评测数据集
HyperAI超神经
·

核心转储流行病学:修复一个存在18年的漏洞
OpenAI
·
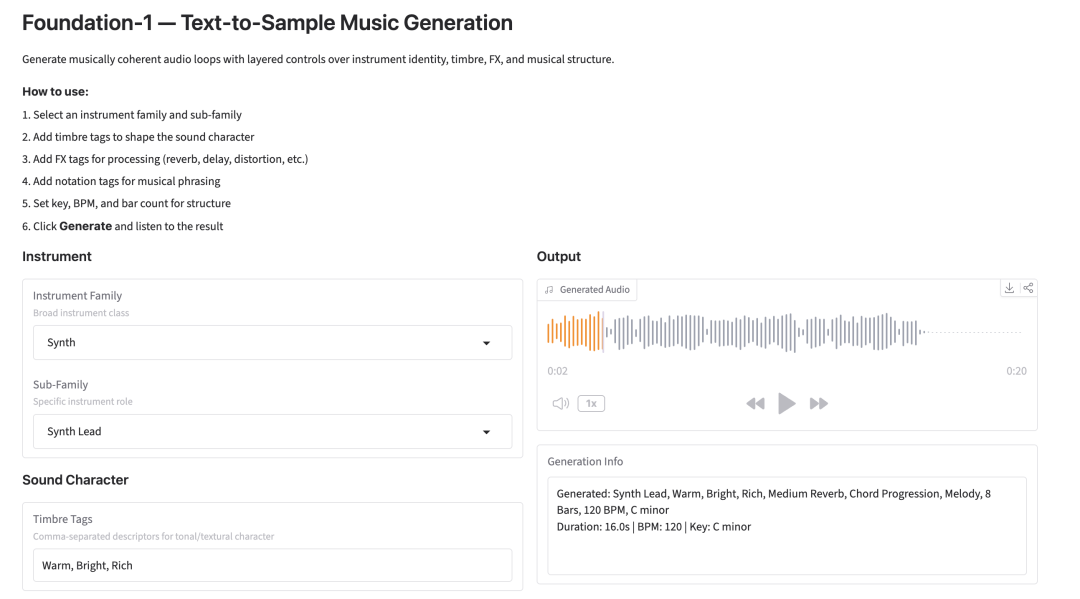

如何在亚马逊云科技上构建企业级智能体
亚马逊AWS官方博客
·

医疗影像中的隐性PHI问题:构建用于AI去标识化的合成数据集
freeCodeCamp.org
·
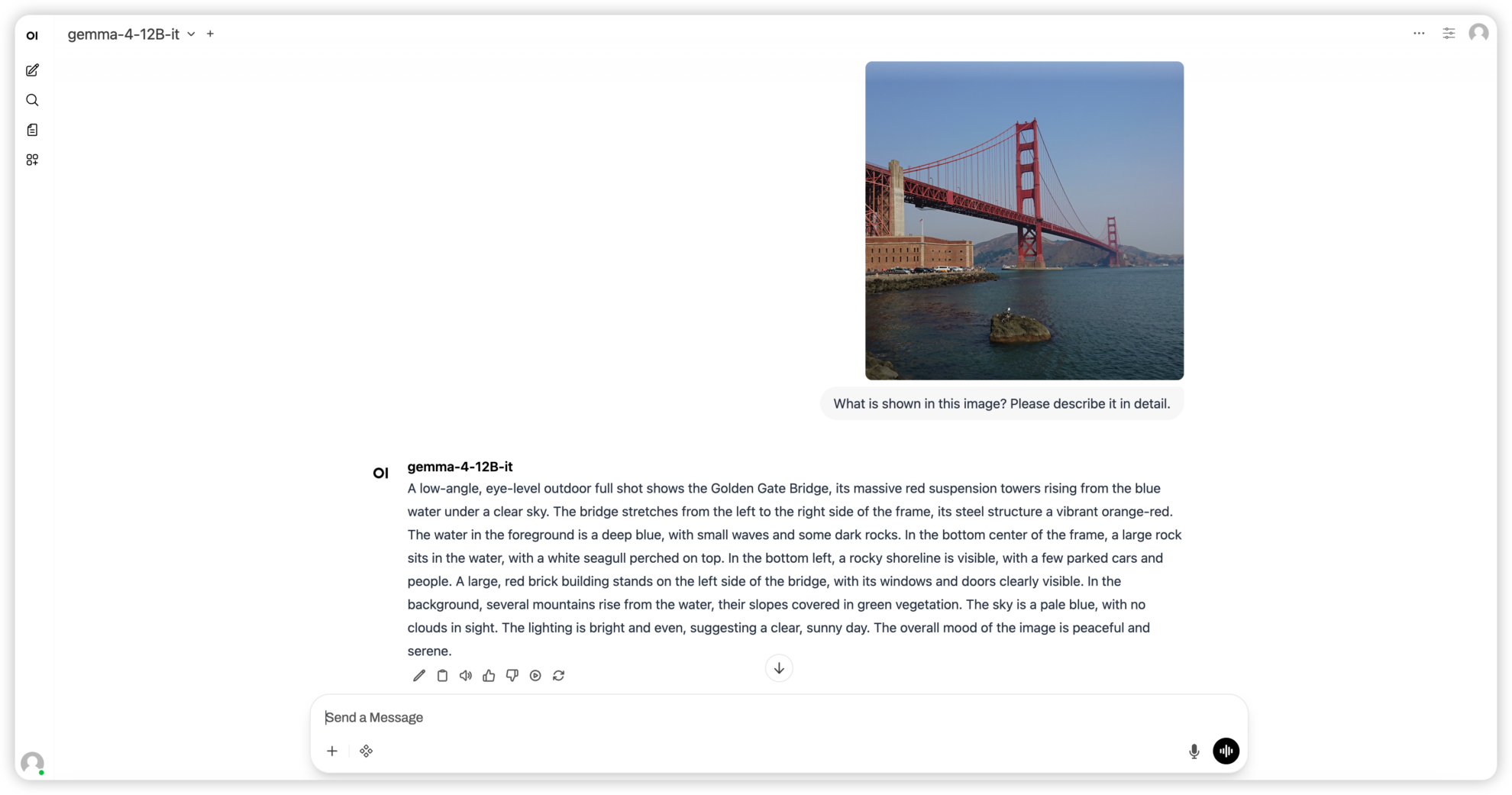
通过新的开放数据集加速研究人员和开发者构建多语言AI
The GitHub Blog
·
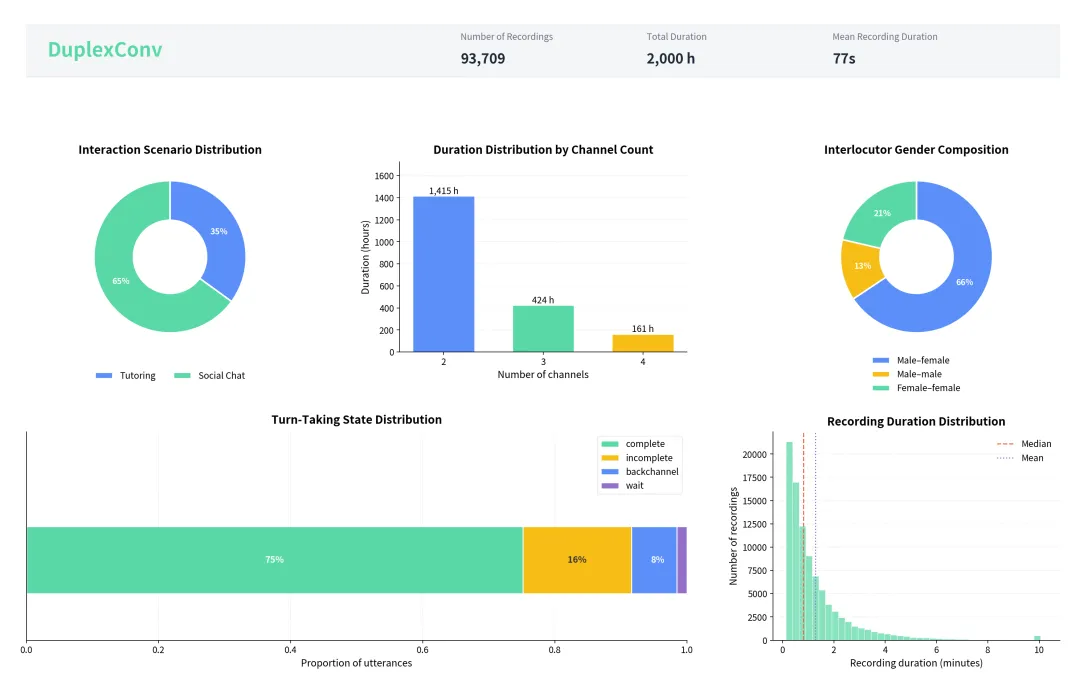
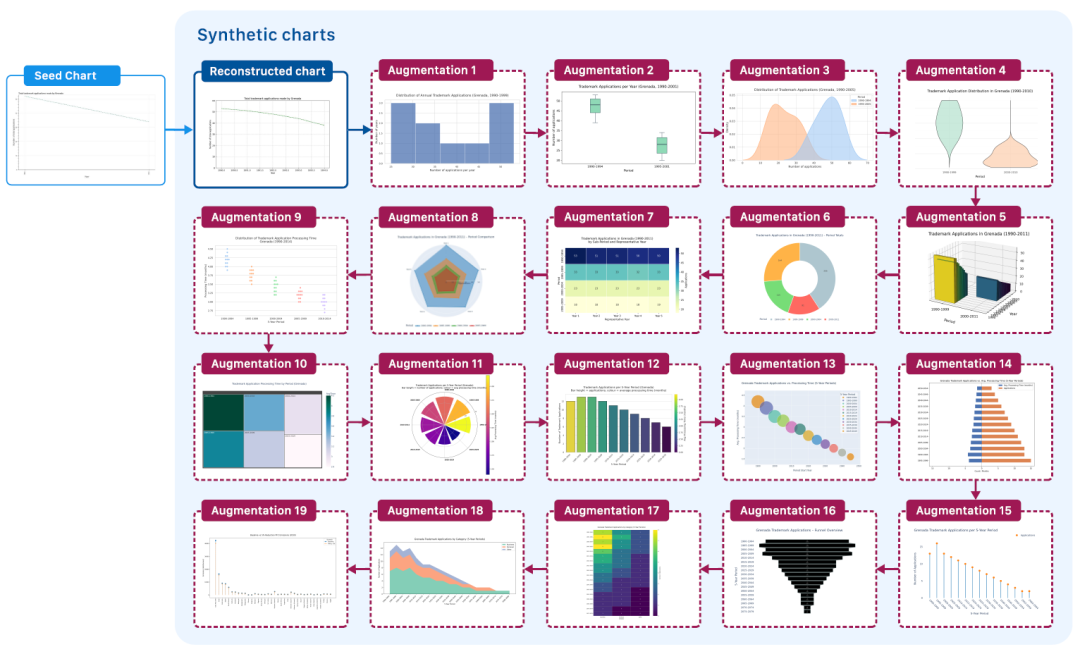
麻省理工/IBM提出迄今为止最大的合成图表数据集ChartNet,生成150万个多样化图表样本
HyperAI超神经
·
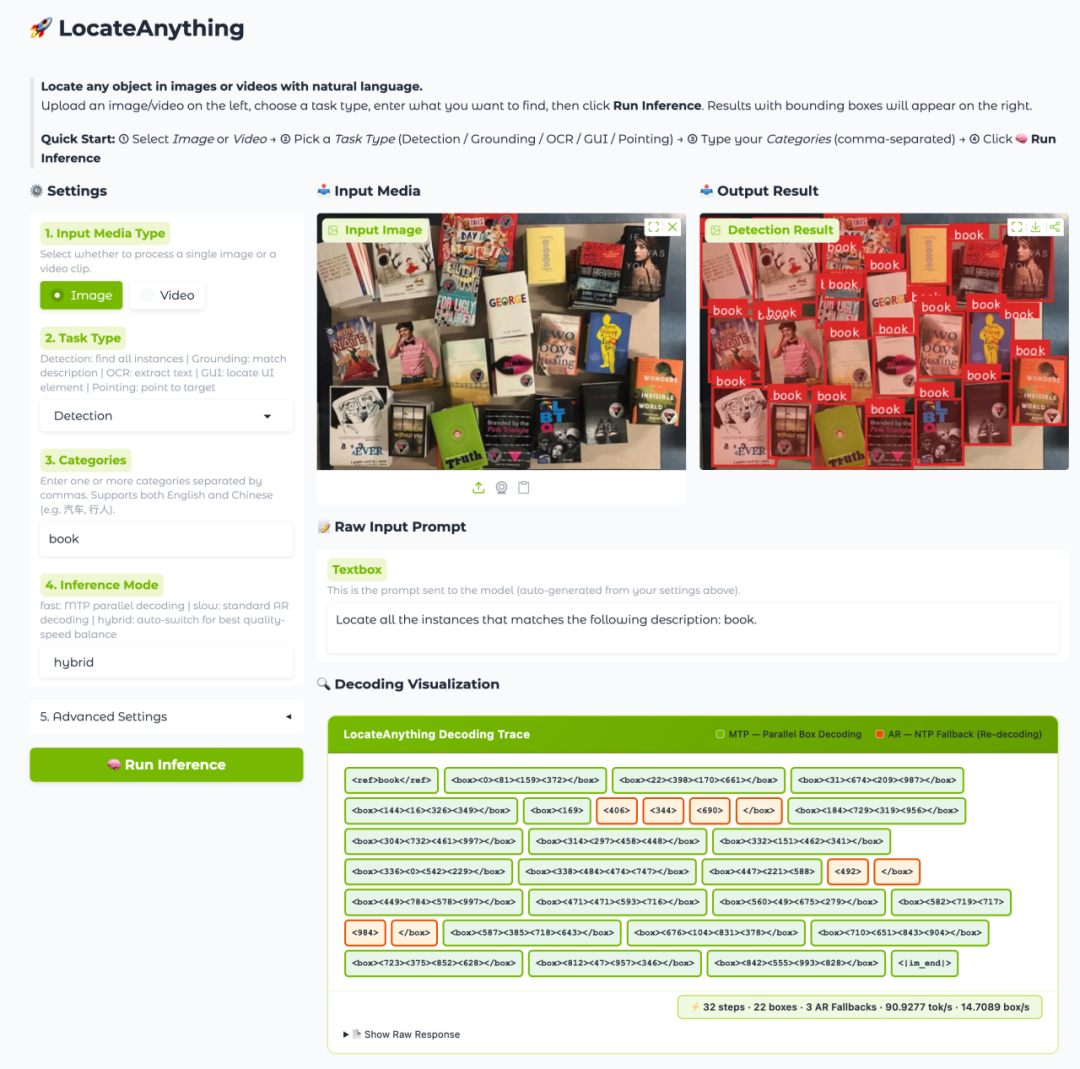
麻省理工学院研究人员教AI模型解读图表
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·