
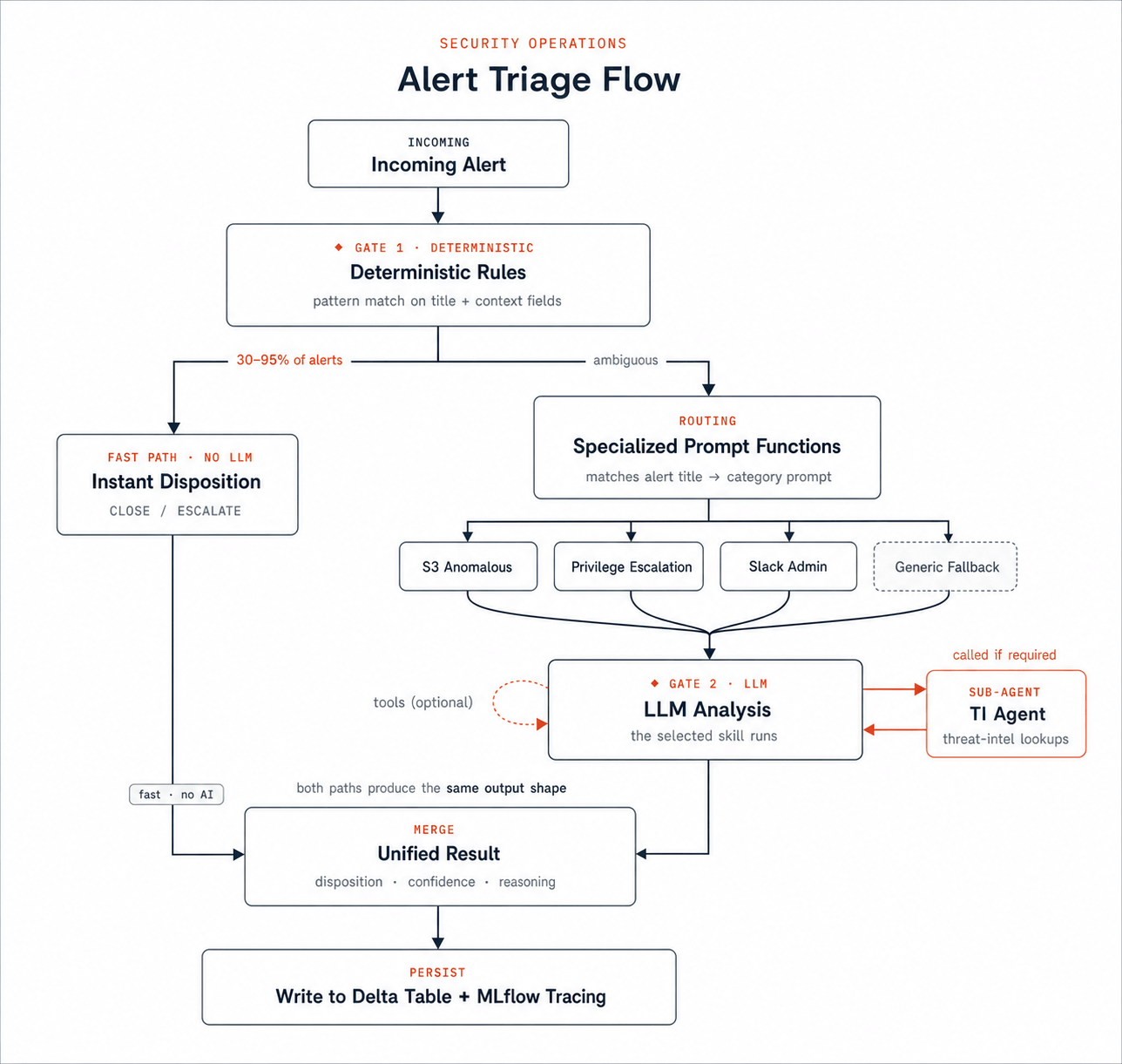
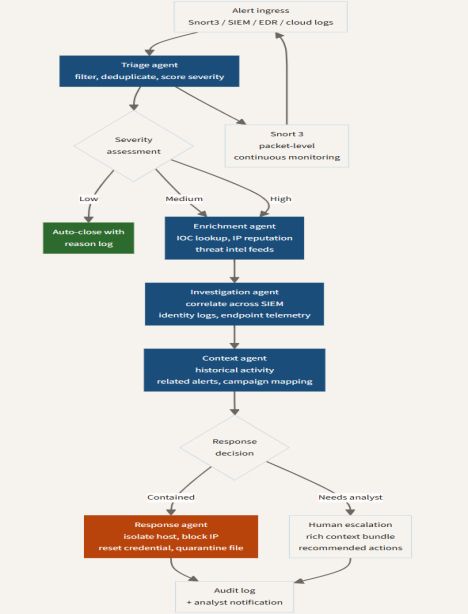
当传感器开始思考:SnortML、代理AI与入侵检测架构的演变
Stack Overflow Blog
·
2026年伯克利人工智能研究实验室毕业生展示
The Berkeley Artificial Intelligence Research Blog
·


三个问题:超越数据驱动的美学
MIT News - Artificial intelligence
·

在机器学习环境中使用Amazon SageMaker AI防止数据泄露
AWS Architecture Blog
·
评估GitHub Copilot代理工具在不同模型和任务中的性能与效率
The GitHub Blog
·

Meta:在实时通信(RTC)领域大规模采用 AV1
实时互动网
·

Databricks连续第二年在Gartner魔力象限中在执行力和愿景方面位居最高
Databricks
·

1小时真机RL微调成功率破95%!HIL-ResRL:即插即用的VLA“外挂”神器
mongona news
·
TPU开发者中心:高性能AI平台的技术评审
mongona news
·
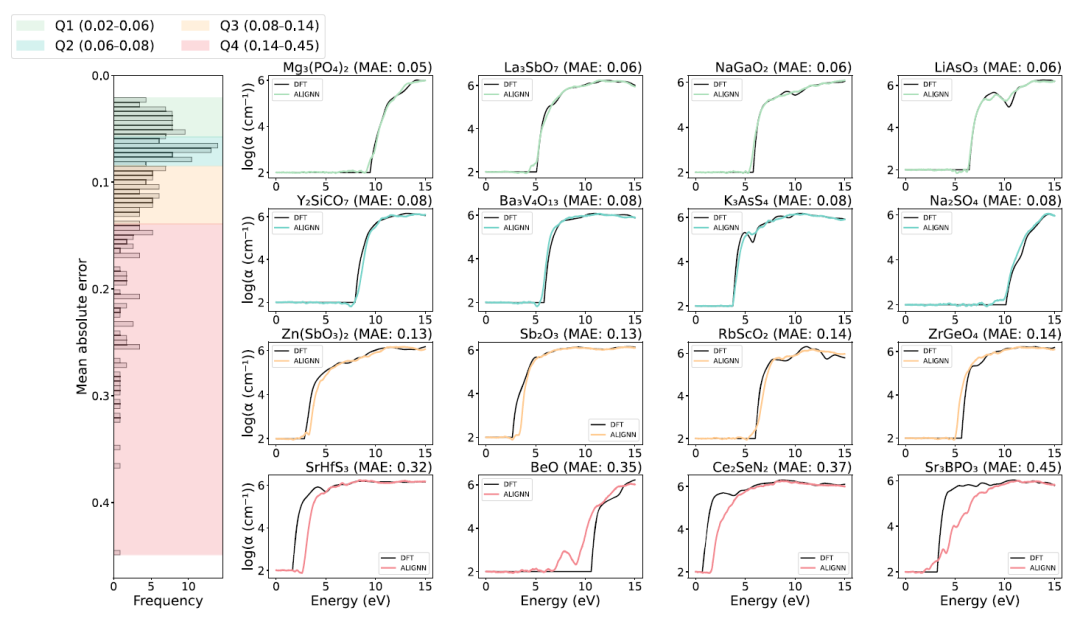
材料AI迈向「可解释时代」,日本团队破解高维光谱黑箱,锁定新材料发现关键特征
HyperAI超神经
·

你的智能代理想要像2010年的量化分析师一样进行搜索
The New Stack
·

更好的金属合金行为建模方法
MIT News - Artificial intelligence
·
