ExtraVM达拉斯机房提供VPS服务,起价每月5.5美元,配置包括AMD双核处理器、4GB内存、60GB NVMe存储和10TB流量,速度为5Gbps。
Cloudflare推出可编程流量保护,允许Magic Transit客户自定义DDoS缓解逻辑,针对UDP协议进行精确防护。客户可通过编写eBPF程序定义数据包的好坏,增强DDoS攻击防御能力。目前该系统处于测试阶段,面向企业客户提供。
CloudCone的KVM VPS服务起价为$14.99/年,配置包括2核CPU、1GB内存、20GB SSD存储和1Gbps带宽,数据中心位于洛杉矶。
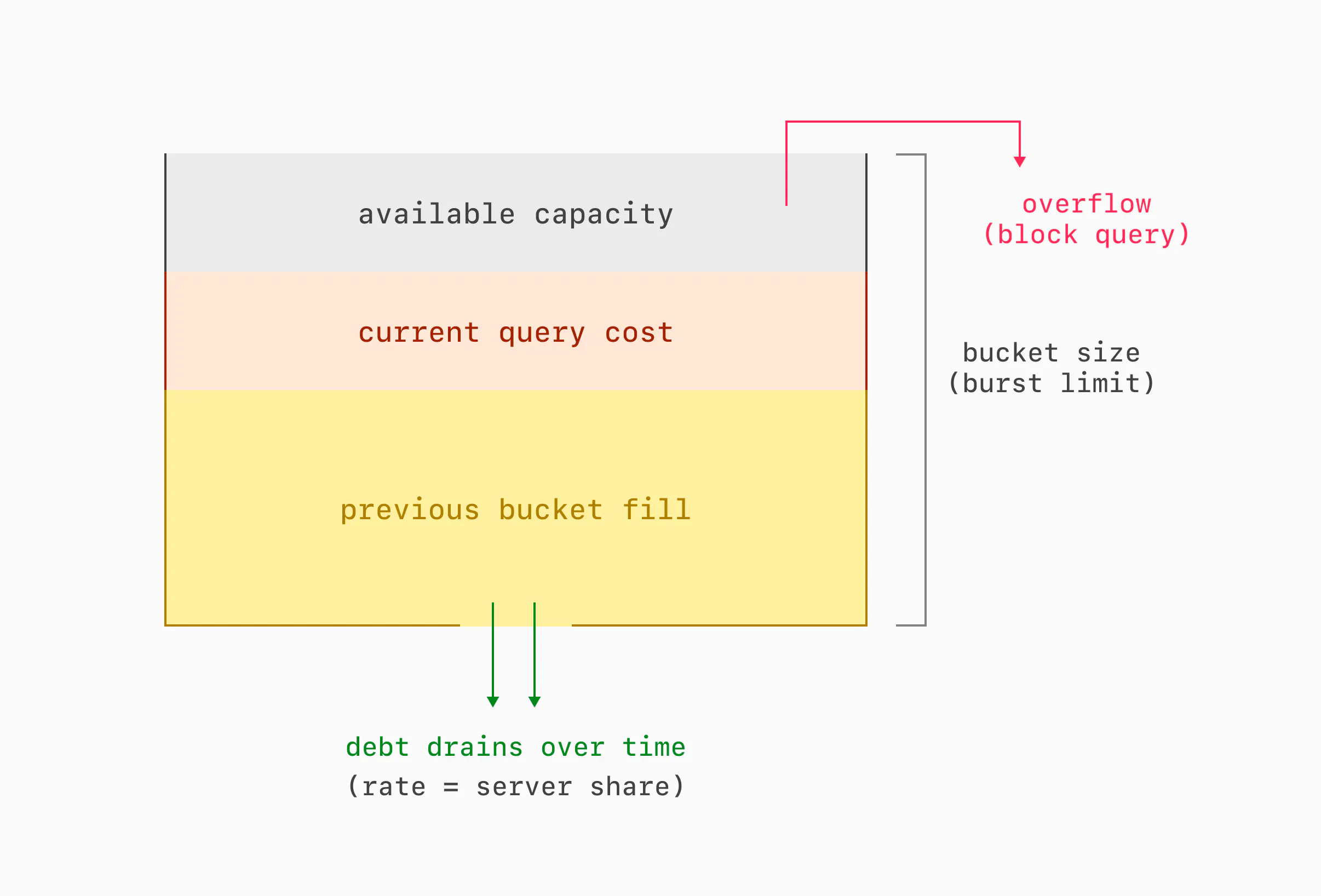
SQL查询规划器选择高效的执行步骤并估算成本。使用EXPLAIN命令,Postgres展示每个步骤及总成本,成本以无量纲单位表示,受可配置权重影响。计划成本大致线性,实际资源消耗与查询、服务器及当前负载相关。
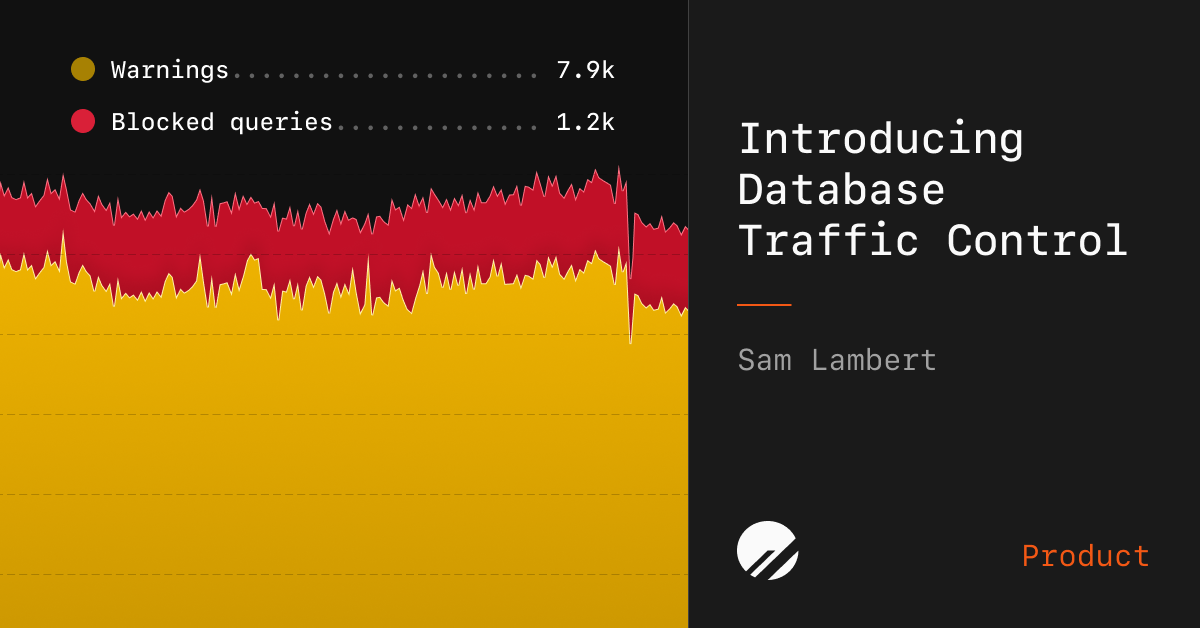
PlanetScale Insights 追踪每个查询的统计数据,帮助用户识别问题查询,查看详细使用数据,并设置预算限制。
野草云在香港推出云服务器特惠,年付仅88元,独立服务器月付199元起,支持多种配置和主流AI服务,满足不同用户需求。
Cloudflare CEO马修·普林斯预测,未来1~2年内,AI机器人产生的互联网流量将超过人类,目前机器人流量占比为30%。生成式AI的兴起将加速这一趋势,可能导致互联网运作方式的重大转变。
社交媒体X/Twitter将推出点踩和AI举报按钮,以打击垃圾内容和未标注的AI生成内容。点踩功能仅限于回复,举报分为AI生成和垃圾信息。发布垃圾内容的创作者收益将变为负值,用户可限制评论区域以减少AI评论干扰。
iWebFusion提供独立服务器,起价$45/月,配置包括E3-1230v2、16GB内存和1Gbps带宽,洛杉矶有6个机房可选。
Cloudflare R2 对象存储免收出口流量费,解决了图床流量盗刷问题。兼容 S3 API,提供免费额度,适合个人用户。用户可通过缓存、速率限制和防盗链等措施增强安全性,安心管理图片。
谷歌的AI概览功能导致部分网站自然搜索流量下降高达97%。虽然AI能节省用户时间,但也可能提供错误信息。流量下降的原因包括用户搜索频率降低和Reddit排名上升。谷歌对此表示否认,称报告未考虑季节性波动。
伊朗自2月28日起因美国和以色列的军事行动切断国际互联网,流量降至正常的0.1%,已断网超过72小时。此举旨在防止敌对国家监视,部分民众通过星链系统访问互联网,但连接可能受到干扰。
【TechWeb】3月3日消息,近日,OpenAI因政治献金丑闻和军方交易引发众怒,一场轰轰烈烈的“QuitGPT”运动将Claude推上了苹果App...
由于百度爬虫无节制抓取博客园,导致其流量被封杀,博客园面临生存困境,原创内容质量下降,内容生态受到冲击,提醒程序员关注优质技术内容。
Kubernetes宣布Ingress-NGINX将于2026年退役,用户可迁移至Amazon Load Balancer Controller或Gateway API。本文提供详细的迁移方案,包括架构差异、功能对比及配置示例,确保EKS用户实现零停机迁移。
2026年视频流量主战场已锁定,Veo API推出,帮助用户低成本、高效率生成高清商业视频,解决专业剪辑难题,适用于自媒体、电商和企业培训等场景,提升内容质量与变现能力。
黑客控制了1999年注册的域名7zip.com,假冒7-Zip分发恶意软件,利用受害者的IP地址作为代理,难以被检测。安全公司已更新病毒库以拦截该域名。
独立开发者阿小信在接入微信支付时遇到诸多挑战,最终成功实现支付功能。同时,他因AdSense收入下降感到焦虑,计划通过优化内容和SEO策略来改善现状。
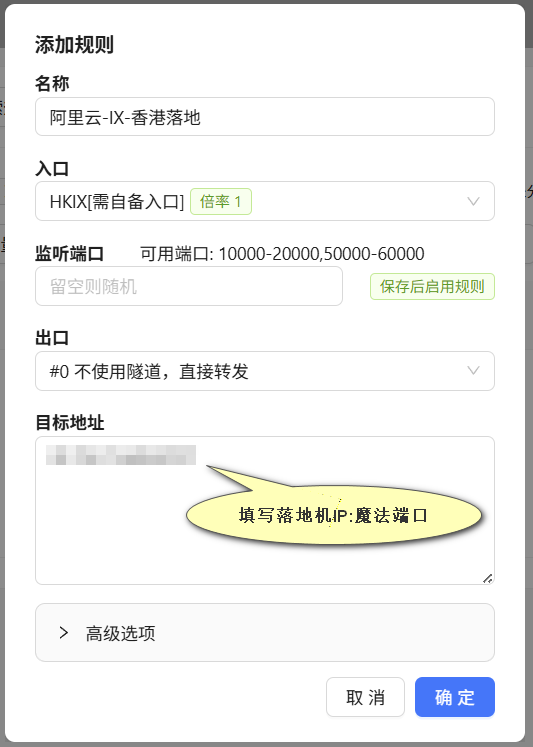
AKCDN是一家新兴的流量转发服务商,提供低门槛套餐(5元200GB流量)。用户需自备VPS和落地机,使用ny面板设置转发规则,适合流量需求不大的用户。
黑客利用React2Shell漏洞入侵宝塔面板和NGINX服务器,篡改配置文件,将流量重定向至非法博彩网站,主要针对印度、印尼和泰国等国。管理员需定期检查配置文件以防止劫持。
完成下面两步后,将自动完成登录并继续当前操作。









![7zip[.]com竟然是黑客搭建的钓鱼网站 安装代理软件把用户系统当肉鸡中转流量](https://img.lancdn.com/landian/2026/02/111811.png)