


相似度算法调研
像清水一般清澈透明
·

理解Dijkstra算法
freeCodeCamp.org
·
我们对生物韧性的研究方法
Google DeepMind Blog
·

X承认其算法存在问题,使得网站感觉像是一个‘战场’
The Verge
·


那些让人笑出声的Meme排序算法
iTimothy
·
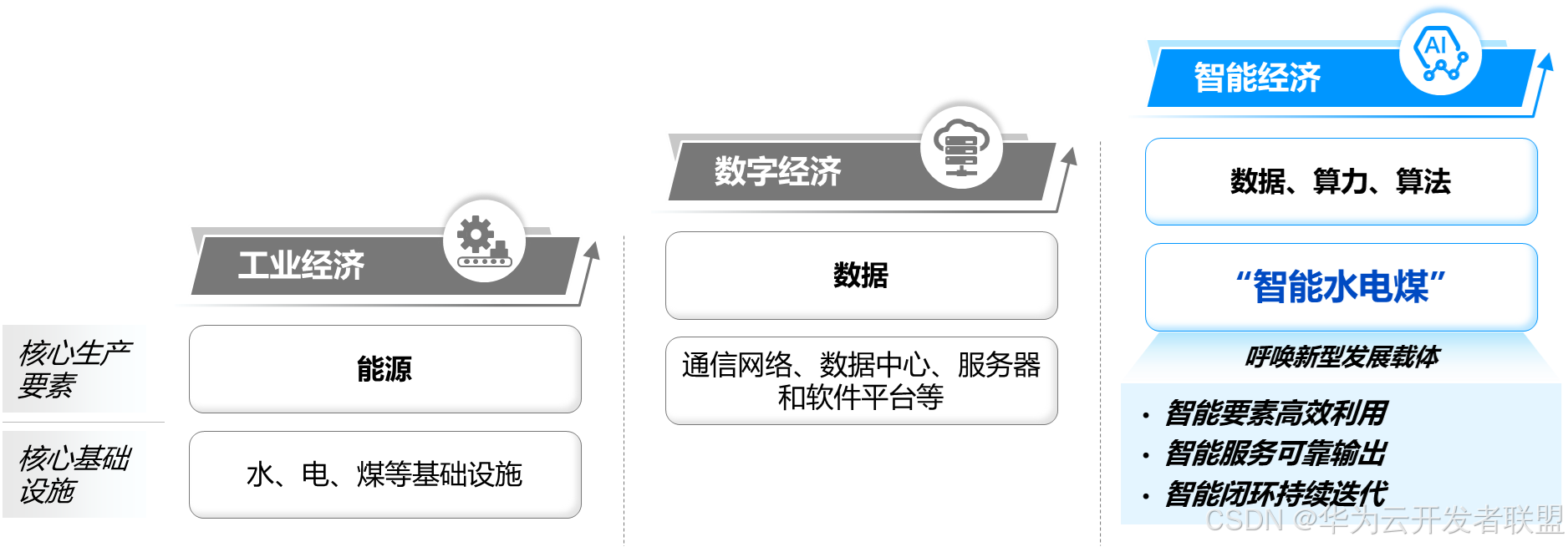
【公共云三十问 之二】为什么公共云成为智能时代的“水电煤”?
华为云官方博客
·

中国算法养蛊罐,为什么能孵出全球妖怪?
硕鼠的博客站
·
