

Stefanie Janine Stölting:pgsql_tweaks 1.0.4版本发布
Planet PostgreSQL
·
斯特凡妮·雅尼娜·斯特尔廷:pgsql_tweaks 1.0.3版本发布
Planet PostgreSQL
·

使用yii3实现一个微框架
f2h2h1's blog
·
Anthropic的Claude Code代理视图是一个更好的仪表板。那么,为什么开发者们仍然不信服呢?
The New Stack
·

Learn Vim 第二十章:视图、会话和 Viminfo
Eric's Blog
·
Claude Code中的代理视图
Claude
·

Radim Marek:对PostgreSQL视图的深刻见解
Planet PostgreSQL
·

MediaKind分享多视图部署最新进展
实时互动网
·

现在YouTube TV允许您多视图观看任何您想要的频道
The Verge
·

Fubo 将在 LG 电视上推出多视图功能
实时互动网
·
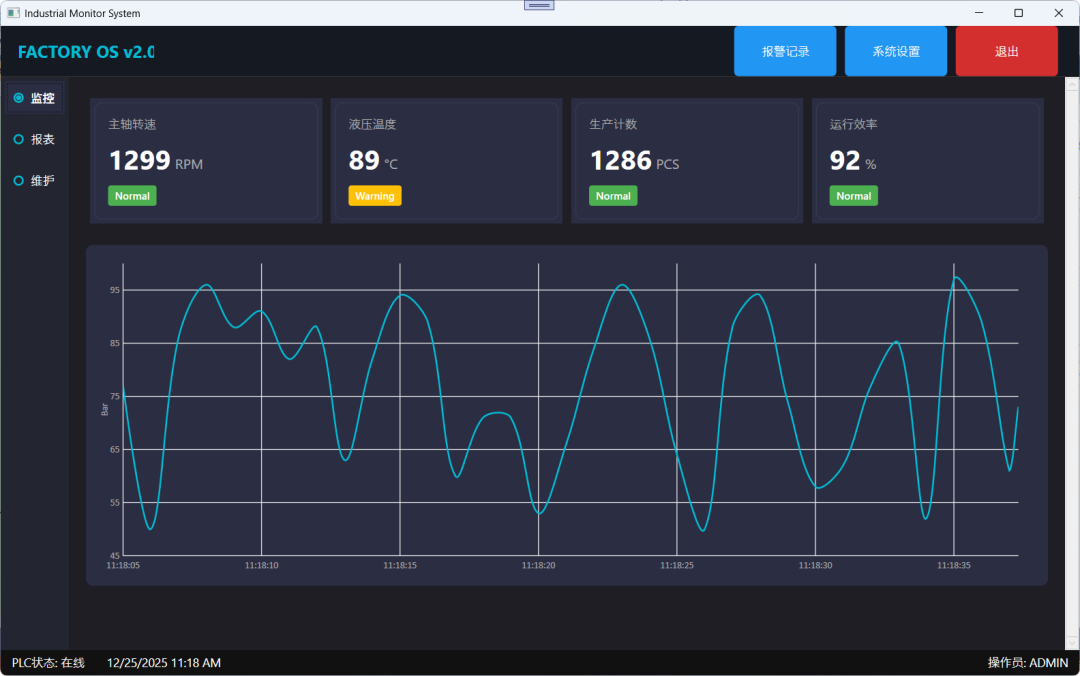
WPF 工业监控视图模型:实时转速、温度、压力曲线全搞定
dotNET跨平台
·

