
AI原生时代来临,商汤大装置如何重塑算力集群架构
量子位
·

一天重写 JSONata,我用 400 美元干掉了公司 50 万美元的 K8s 集群
Tony Bai
·

如何使用kcp在不增加开销的情况下运行多个Kubernetes集群
freeCodeCamp.org
·

如何保护Kubernetes集群:RBAC、Pod加固和运行时保护
freeCodeCamp.org
·

Istio推出未来就绪的服务网,迎接AI时代,带来新的环境多集群、Gateway API推理扩展等功能
Cloud Native Computing Foundation
·

肖恩·托马斯:使用Patroni构建高可用性Postgres集群——第三部分:HAProxy
Planet PostgreSQL
·
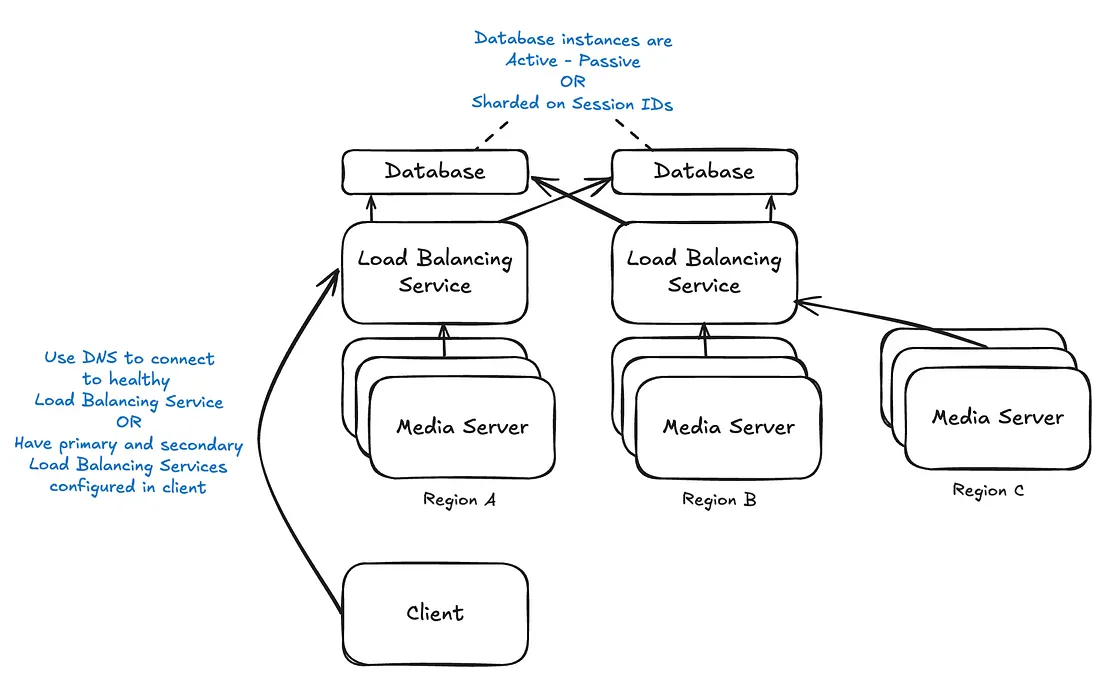
如何在服务器集群发生故障时 WebRTC 架构仍能正常运行?
实时互动网
·

扩展自主站点可靠性工程:90,000+服务器集群的架构、编排与验证
The DigitalOcean Blog
·
肖恩·托马斯:使用Patroni构建高可用Postgres集群——第二部分:Postgres与Patroni
Planet PostgreSQL
·
/filters:no_upscale()/news/2026/03/uber-mysql-uptime-consensus/en/resources/1rebalance-1772309210665.jpeg)
从分钟到秒:Uber通过共识架构提升MySQL集群的可用性
InfoQ
·
/filters:no_upscale()/news/2026/03/netflix-automates-rds-aurora/en/resources/1enablementoverview-1772246270071.jpeg)
为什么当仪表板看起来正常时,你的Kubernetes集群还在添加节点?
The New Stack
·

Kubernetes的自我修复是如何工作的?通过破坏真实集群来理解自我修复
freeCodeCamp.org
·
肖恩·托马斯:使用Patroni构建高可用Postgres集群——第一部分:etcd
Planet PostgreSQL
·

谷歌提升GKE集群节点池自动创建速度
InfoQ
·
/filters:no_upscale()/news/2026/02/cilium-119/en/resources/1Screenshot From 2026-02-25 22-31-58-1772059001466.png)

构建Prometheus:后端聚合如何支持千兆瓦级AI集群
Engineering at Meta
·

Kubernetes遥测功能完全危害集群
The New Stack
·
