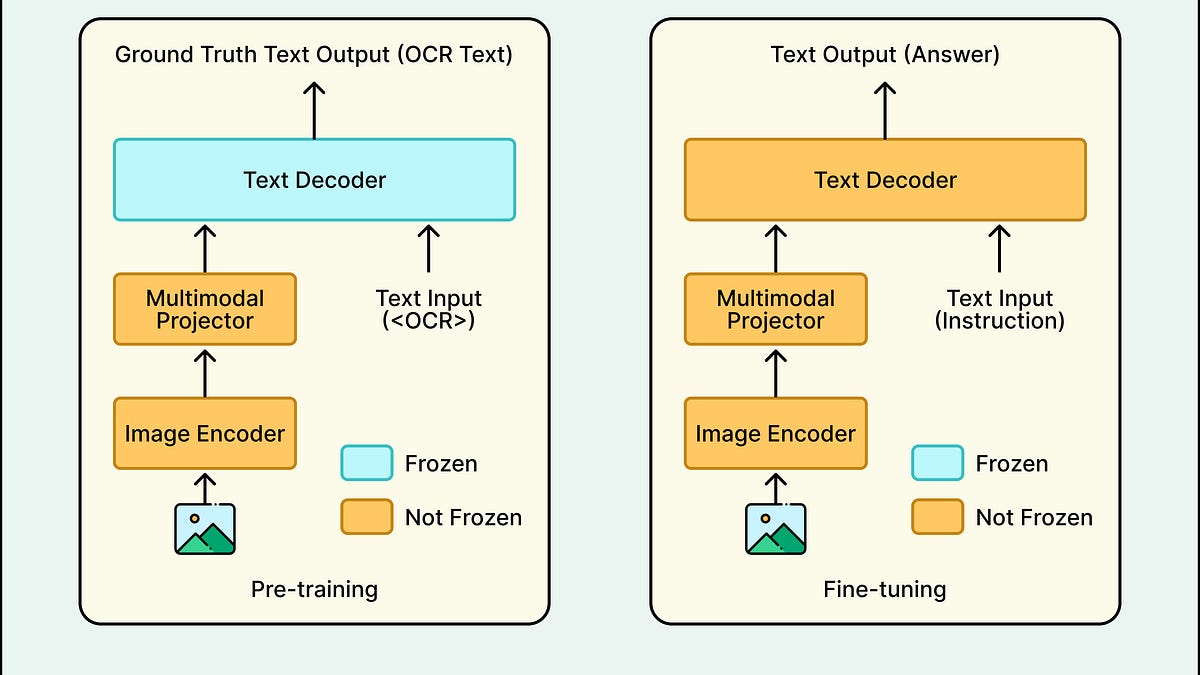
Grab团队开发了一种轻量级视觉大语言模型(Vision LLM),旨在提升东南亚语言的文档处理能力。通过合成数据和自动标注框架Documint,优化了OCR和关键信息提取的准确性,最终模型在准确性和延迟方面表现优异,展示了专用模型在文档处理中的潜力。
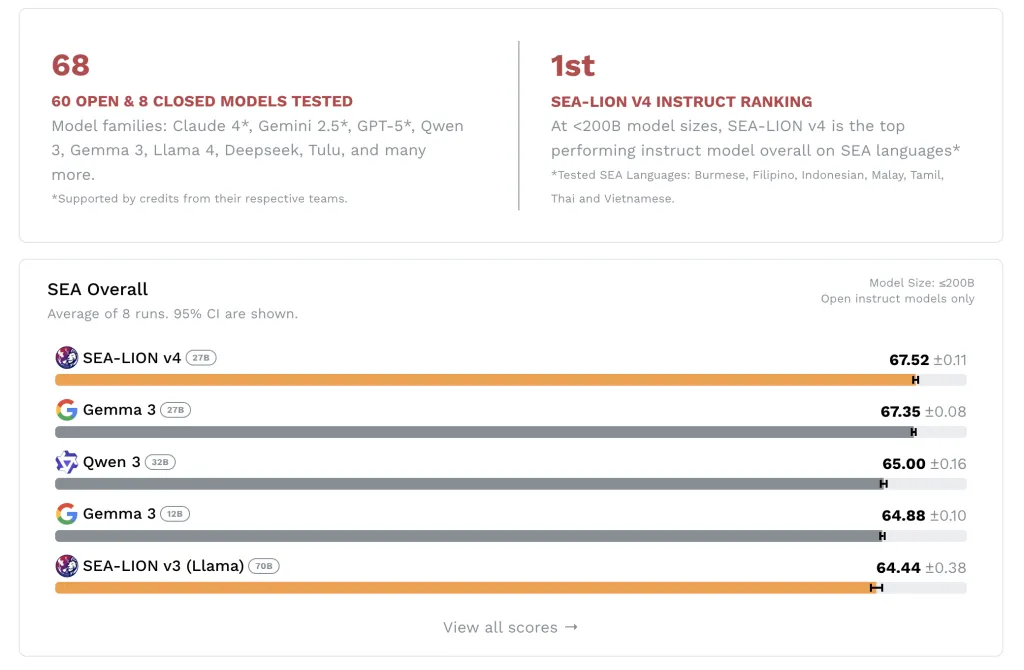
新加坡人工智能研究院发布的SEA-LION v4是一个开源的多模态语言模型,支持东南亚语言,具备文本和图像理解能力。该模型在多项语言任务中表现出色,尤其在资源匮乏的语言上,推动了数字公平。设计高效,适合多平台部署,适用于研究和行业应用。
本研究提出了SEA-HELM评估套件,旨在填补现有语言模型评估工具在东南亚语言方面的不足。该套件基于五个核心支柱,强调东南亚语言的多元文化特性,提供用户全面理解模型表现的平台,推动东南亚语言模型的研究与应用。
本研究开发了针对东南亚语言的多语言模型水手2,填补了资源缺口。该模型在500B标记上预训练,支持13种东南亚语言,并在中文和英语上表现流利。在与GPT-4o的对抗中,水手2模型的胜率达到50%,预计将推动该地区语言的发展。
本文介绍了针对东南亚语言的创新语言模型SeaLLMs和CompassLLM,旨在解决大型语言模型在低资源语言中的偏差问题。SeaLLM-13b在泰语、高棉语等非拉丁语言上表现优于ChatGPT-3.5。Sailor模型在多项基准任务中表现出色,BHASA提供语言和文化评估工具。研究表明,模型规模和训练数据质量对性能影响显著,呼吁在低资源NLP情境中谨慎应用相关技术。
完成下面两步后,将自动完成登录并继续当前操作。