最新SuperCLUE报告显示,豆包1.5和商汤日日新V6并列国内大模型第一,超越Gemini 2.5,表明国产模型在中文领域能力显著提升。
Llama 4发布了三个版本,支持1,000万TOKEN的长上下文,并采用混合专家模型。尽管中文能力有所提升,但与主流模型相比进步不明显,市场反响平淡。开源模型竞争激烈,千问和DeepSeek等已具备可用性,Meta需寻找新应用场景以保持竞争力。
DeepSeek是中国推出的开源推理大模型,具备强大的中文处理能力和金融优势。其V3和R1模型参数达到6000亿,适合深度思考场景。因低成本和开源特性,DeepSeek迅速流行,背后有强大资金支持和高水平团队。
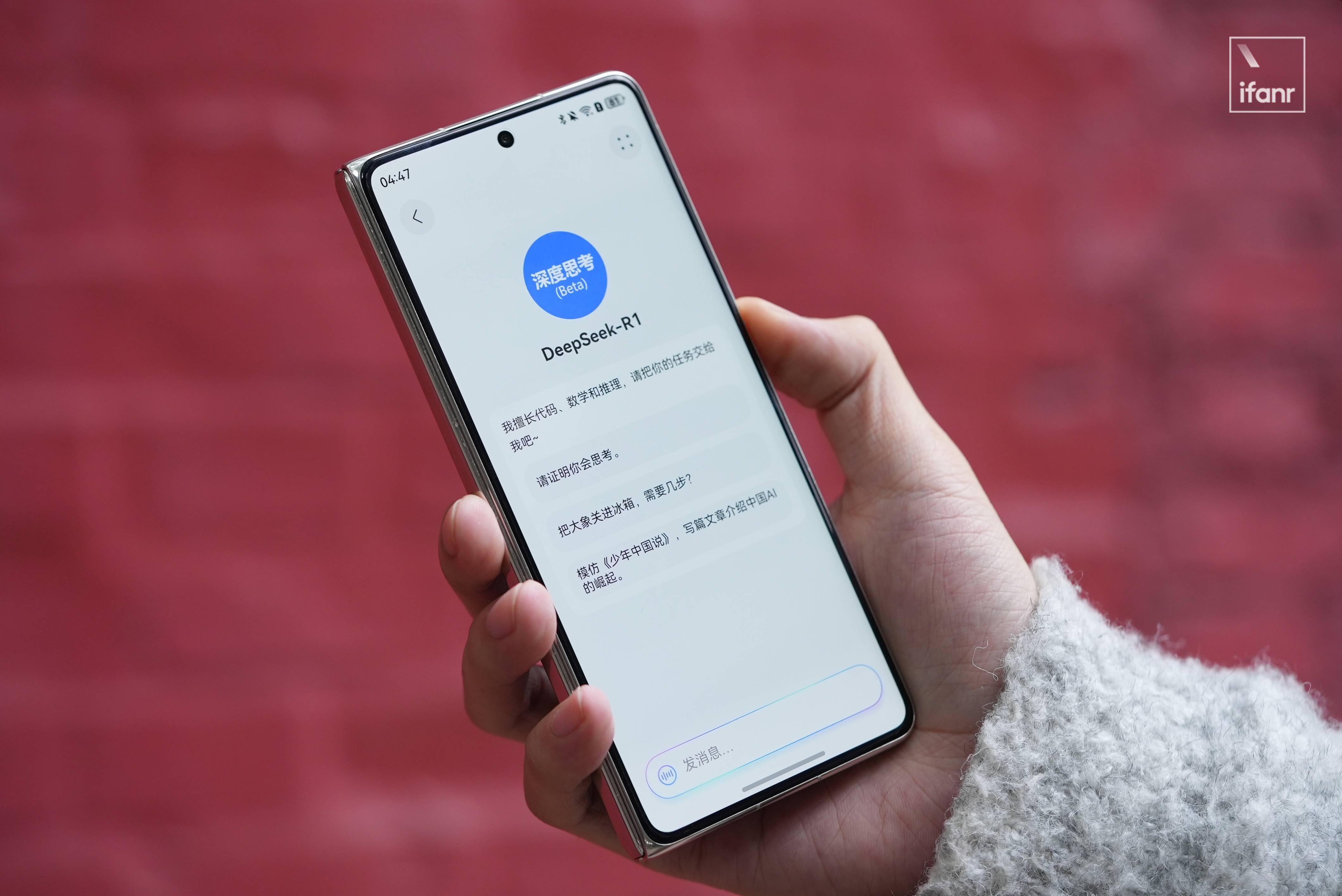
春节期间,AI工具DeepSeek在中国迅速流行,因其低成本和强大的中文能力吸引了众多云平台接入。华为小艺助手首次集成DeepSeek-R1 Beta,界面简洁,支持语音输入,但上下文长度和回答准确度仍需提升,整体适合日常简单问题,未来有待改进。
智源研究院发布了100余个大模型的综合评测结果,涵盖文本、语音、图像和视频等多模态。评测显示,国内模型在中文能力和复杂场景任务上与国际水平仍有差距。新评测增加了金融量化交易等应用能力的评估,发现大模型在生成策略代码方面已有进展。整体来看,模型能力显著提升,但仍需改进。
本文介绍了以羊驼为名的大型语言模型LLaMA和Alpaca的发布,这些模型在中文能力上有显著提高。周边配套工具已自成生态。呼吁AI人人可用,希望在不久的将来实现。
完成下面两步后,将自动完成登录并继续当前操作。