中科院、北电数智等专家共探数学与AI边界
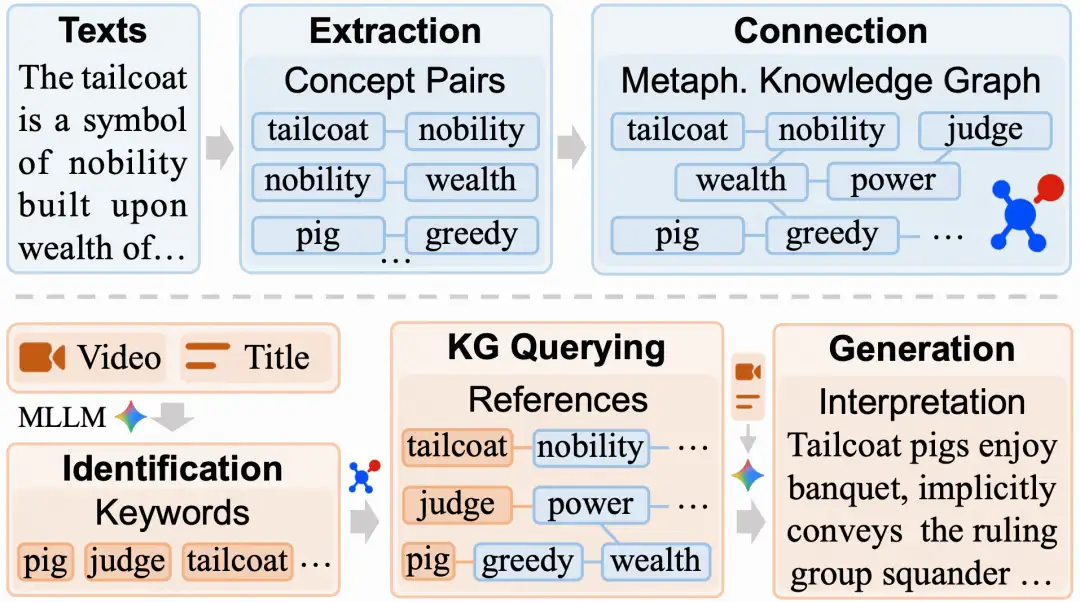
在短视频和社交媒体时代,创作者通过隐喻表达深层意涵。快手与科研机构合作,提出隐喻视频理解基准MetaphorVU,以提升多模态大模型的隐喻理解能力。研究发现现有模型在跨域映射上存在不足,导致理解失败。为此,团队开发了MetaphorBoost,通过隐喻知识图谱增强模型理解能力,取得显著提升。这项研究为多模态理解提供了新的评测标准和增强路径。
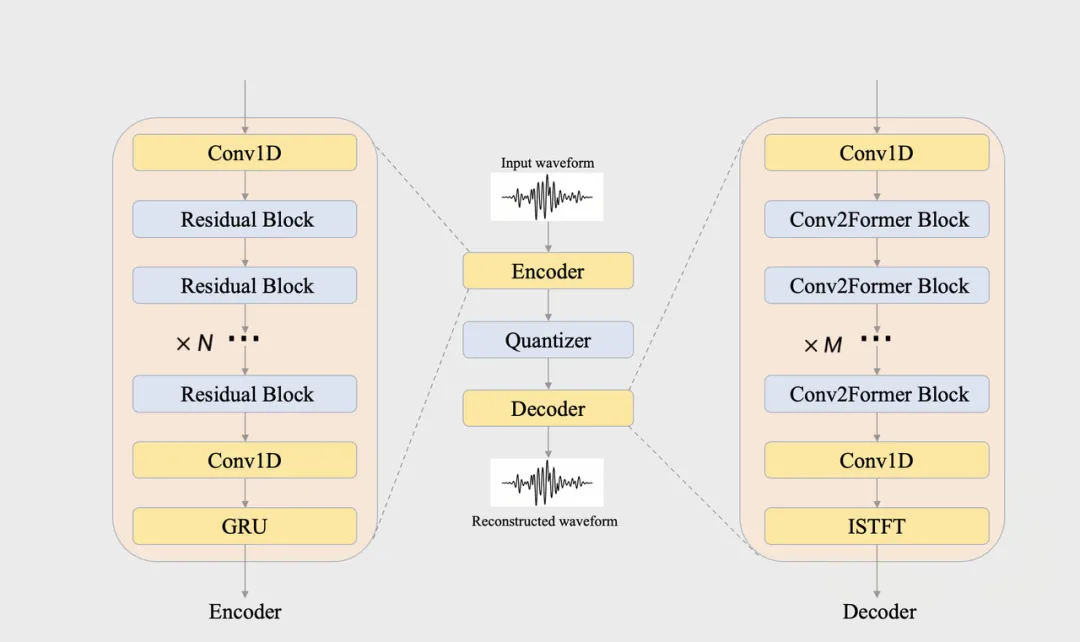
2025年低资源音频编解码器比赛吸引了多家机构参与,字节跳动团队表现优异,获得赛道1冠亚军和赛道2季军。比赛聚焦低复杂度、高音质的音频编解码技术,推动实时通信和流媒体的发展。团队提出的IRIS和Enhance-Nanocodec方案在严格限制下实现了优质音频重建,未来将继续优化技术,拓展应用场景。
高德与中科院合作的ABot-NeoVerse团队在ICRA 2026 AGIBOT挑战赛中以0.829的成绩夺冠,领先150支队伍。该赛事聚焦推理与世界模型,ABot技术体系通过自研世界模型合成高仿真训练数据,解决了具身智能的数据稀缺问题,展示了高德在该领域的技术优势。
中国科技云推出的“数据胶囊”服务,实名用户可免费获得20GB空间,支持网页、S3和WebDAV上传。绑定微信后可直接上传文件,并支持AI工具查询和检索。注册需实名验证,使用方便,适合云同步和文件收集。
抱歉,您提供的文本内容过于简短,无法进行有效总结。请提供更详细的文章内容。
中科院团队提出的GOI“声明式”计算机接口,旨在提高LLM智能体在传统GUI下的成功率和效率。通过自动化复杂操作,GOI使LLM专注于任务规划,成功率从44%提升至74%。该研究为未来AI交互设计提供了新思路。
OCR技术在金融和医疗等领域得到广泛应用,借助深度学习和卷积神经网络,识别精度显著提高。新模型如POINTS-Reader和Granite-docling支持多语言和复杂文档处理,展现出强大潜力。
自2017年提出的Transformer架构成为大模型主流,但在规模扩大后暴露出训练和推理效率问题。中国科学院推出的类脑脉冲大模型“瞬悉1.0”在超长序列处理上表现优异,具备低功耗和高效训练能力。
在高能物理研究中,人工智能(AI)成为处理海量数据的核心工具。AI技术能够有效挖掘复杂模式,优化加速器和探测器性能。AI-Ready数据集需具备高质量特征,以支持机器学习和科学发现。智能体技术提升数据加工效率,推动AI在高能物理中的应用。
中科院与阿里团队提出RefineX框架,通过程序化编辑精炼预训练数据,有效去除噪声并保留文本多样性,使模型在多项任务中的得分提高7.2%。该方法以最小干预剥离噪声,确保数据质量和可靠性。
中科院研发的TC-Light生成式渲染器提升了63%的效率,时序一致性提高20%,有效缩小Sim2Real Gap,支持高质量数据生成,促进具身智能训练。该算法已开源,推动视频编辑和数据扩展的发展。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
地理空间优化在城市建设中至关重要,传统方法存在局限。梁浩健博士在学术年会上介绍了基于分层深度强化学习的城市应急消防设施配置优化研究,提出了动态覆盖注意力模型和自适应交互注意力模型,提升了布局效率和风险评估精度。未来将结合地理信息系统与深度学习,探索更复杂的优化问题。
几个家庭一起去的,免费预约。活动很丰富,有机器人展示体验,力学游戏,科学讲座,演出等等,看起来都是研究生们负责
中科院、清华大学与快手联合提出R1-Reward模型,通过强化学习提升多模态奖励模型的长期推理能力。新算法StableReinforce解决了训练不稳定的问题,显著提升了模型性能,实验结果在多个基准上超越了现有最佳模型。
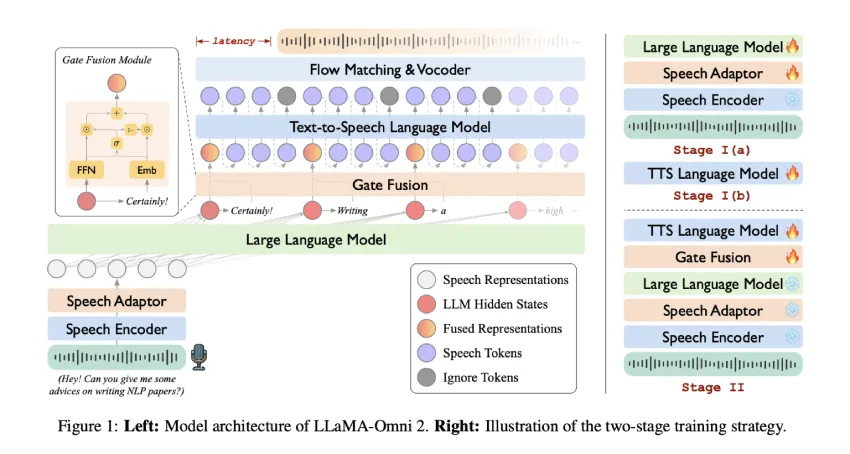
中国科学院计算技术研究所推出的LLaMA-Omni2是一个支持语音的大型语言模型,结合语音感知与语言理解,实现实时口语对话。该模型采用端到端流水线,训练成本低且具有模块化可解释性。在200K语音对话样本上训练后,LLaMA-Omni2的表现优于基线模型,证明高质量、低延迟的语音交互无需大量语料库。
蛋白质在生命活动中至关重要,AI技术正在改变蛋白质设计。罗小舟教授在AI蛋白质设计峰会上分享了多模态学习与生成式AI在酶设计中的应用,提出UniKP框架和ProEnsemble模型,显著提升了酶的预测和优化效率,推动合成生物学发展。
完成下面两步后,将自动完成登录并继续当前操作。