该研究提出了一种自适应提示调优方法,通过交叉注意力机制增强CLIP模型,以应对细粒度分类挑战。该方法动态调整文本提示,实现图像与文本特征的准确对齐,并在多个数据集上显著提升性能和模型预测的可靠性。
本文探讨了组合式零样本学习(CZSL)的新方法,包括因果启发的嵌入模型、交叉注意力机制和类别指定级联网络(CSCNet)。研究表明,这些方法在MIT-States和UT-Zappos等数据集上显著优于现有技术,提升了视觉对象和属性的识别能力,解决了数据不平衡和上下文问题。
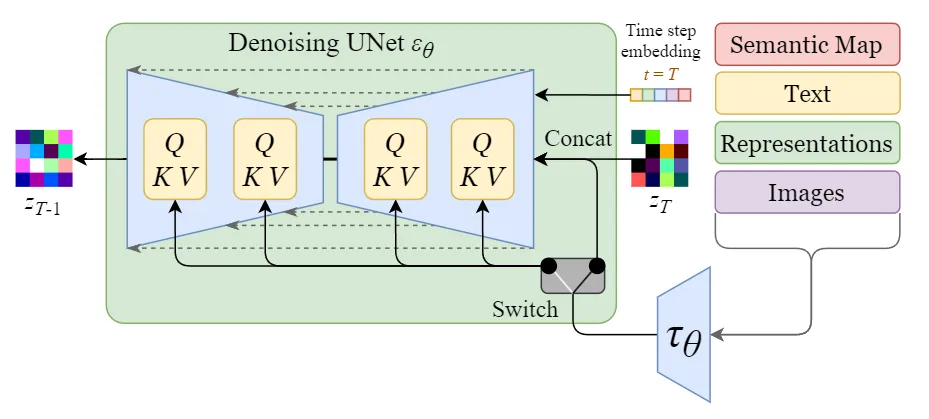
本文介绍了Stable Diffusion(SD)模型中的UNet网络结构。UNet最初用于医学图像分割,经过改造后应用于图像生成。SD的UNet引入了残差模块和Transformer模块,提升了网络的表达能力,并通过交叉注意力机制融合文本提示与图像特征,实现基于文本的图像生成。
本研究探讨了扩散模型在文本到图像合成中的应用,提出通过自动生成描述来改善文本与图像的对齐。研究表明,该方法在多个数据集上提升了模型性能,优化了文本与图像的一致性,并增强了多概念输入图像的处理能力,验证了其有效性。
该研究介绍了一种基于Transformer的注视对象预测方法TransGOP,通过交叉注意力机制改善注视热图回归,并通过注视框损失实现整体框架的端到端训练。实验证明TransGOP在目标检测、注视估计和注视对象预测的任务上取得了最先进的性能。
本研究通过引入基于transformer的CheXFusion融合模块,结合多视图图像处理,利用自注意力和交叉注意力机制,高效聚合多视图特征并考虑标签的共现作用。同时,探索数据平衡和自训练方法以提高模型性能。在MIMIC-CXR测试集中,取得了0.372 mAP的最先进结果,并在竞赛中获得第一名,突显了在医学图像分类中考虑多视图设置、类别不平衡和标签共同出现的重要性。
Stable Diffusion是一种图像生成方法,由Stability AI和Runway基于LDM1提出。该方法通过随机种子生成噪声,利用文本编码器将输入提示转换为向量,并通过Unet网络处理,最终生成高分辨率图像。Unet中加入了交叉注意力机制,提升了生成效果。
完成下面两步后,将自动完成登录并继续当前操作。