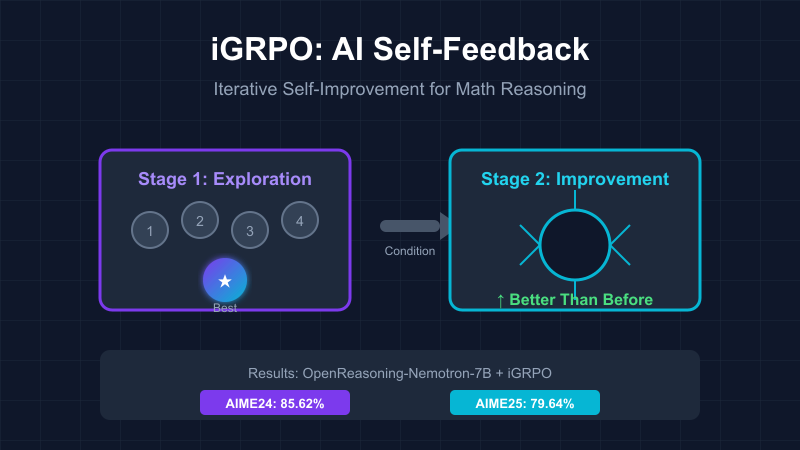
本文提出了iGRPO(迭代组相对策略优化),通过自我反馈提升AI的数学推理能力。该方法包括探索与选择、条件化改进两个阶段,显著提升多个基准测试的表现,且无需复杂的外部反馈。iGRPO的理念与人类学习相似,强调超越自我,具有广泛应用潜力。
大型语言模型(LLMs)被视为先进的预测工具,能够预测序列中的下一个词。尽管它们在人工智能领域引发了革命,但其智能性仍存疑。谷歌DeepMind的研究员周登尼指出,LLMs更像是训练有素的鹦鹉,缺乏人类学习的深度。他强调链式思维提示可以提升LLMs的表现,但也容易受到无关信息的干扰。周的研究旨在让AI更好地模仿人类学习,以推动未来的突破。
完成下面两步后,将自动完成登录并继续当前操作。