


华为自研HBM性能翻倍!昇腾950DT芯片8月提前问世,DeepSeek将优先部署
TechWeb 全站精华
·

NVIDIA Vera CPU在竞争中展现强劲实力
NVIDIA Blog
·
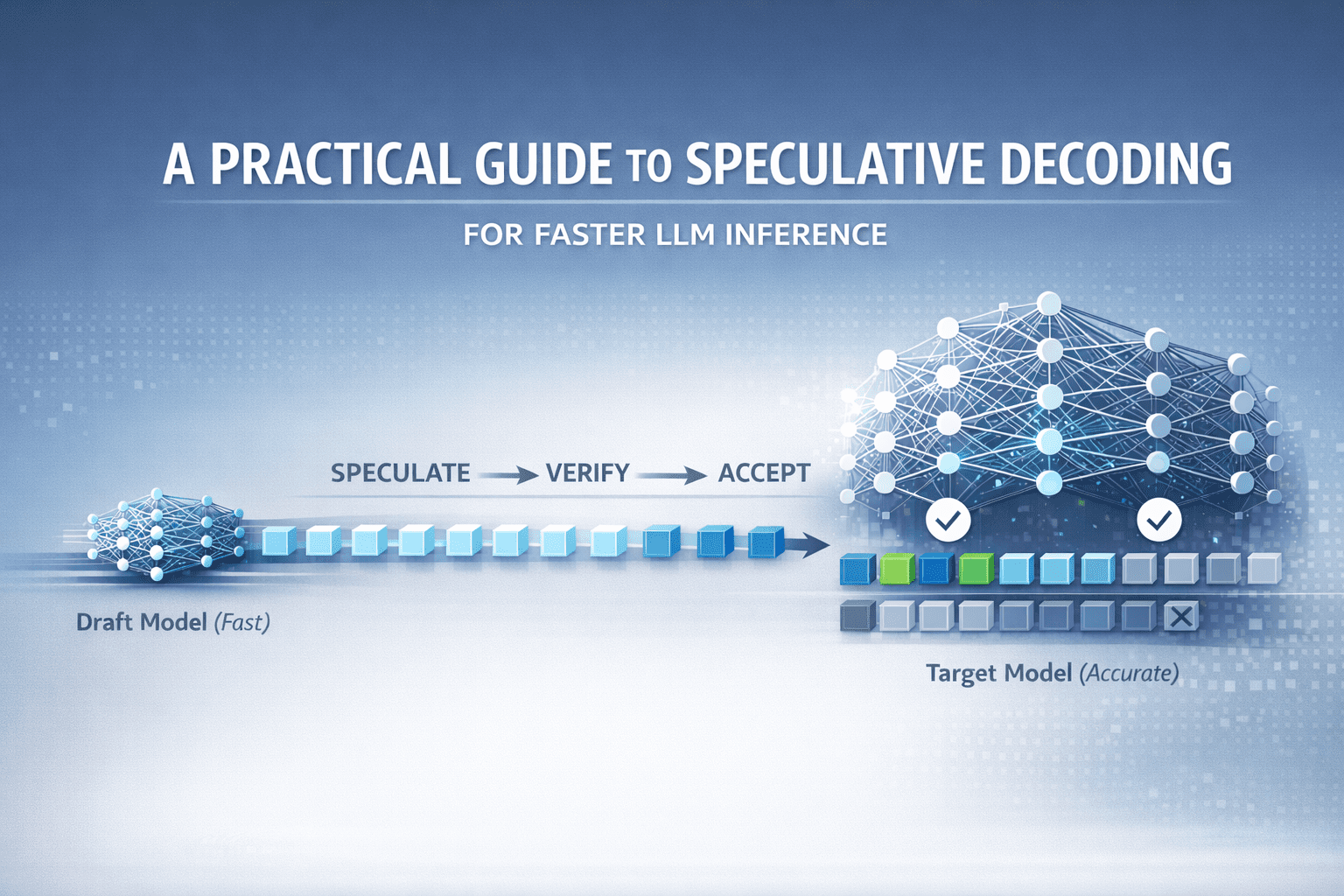
机器学习从业者的推测解码指南
MachineLearningMastery.com
·


全新通用型 Amazon EC2 M8a 实例现已推出
亚马逊AWS官方博客
·

RISC-V 向量内存突破:速度提升 2 倍,功耗降低 30%
DEV Community
·

演讲:释放Llama的潜力:基于CPU的微调
InfoQ
·


独享MRDIMM有多强?至强6性能核处理器的内存二三事
机器之心
·

流量一样但为什么CPU使用率差别很大
plantegg
·
