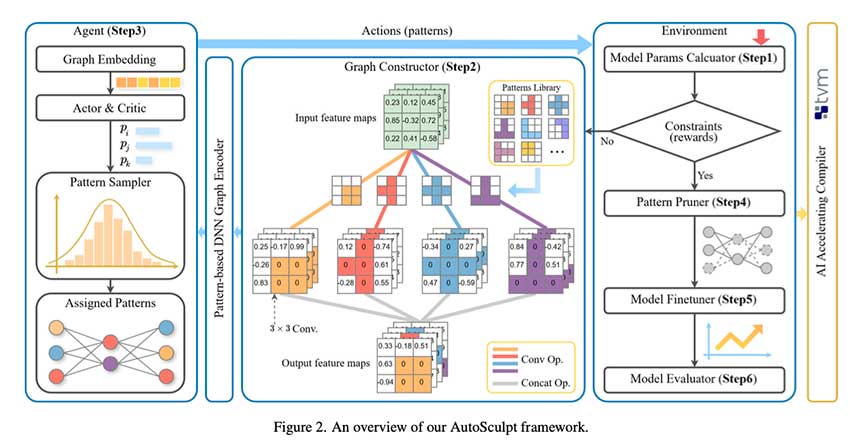
深度神经网络(DNN)在边缘设备部署面临挑战,现有剪枝算法难以平衡压缩率与精度。中国海洋大学提出的AutoSculpt结合图神经网络与深度强化学习,优化剪枝策略,提升硬件兼容性和推理效率。该方法在多种架构上表现优异,显著提高模型压缩效果,适用于资源受限的应用。
该论文探讨了神经网络剪枝算法,提出了NoiseOut和PruneTrain等优化方法,以减少计算和内存开销,同时保持网络精度。研究表明,剪去40-70%的神经元对学习影响不大,且新方法可实现显著加速和压缩。此外,提出了ShrinkBench框架以规范评估剪枝技术。
本文介绍了PruneTrain,一种通过结构化组套骨骼正则化和重新配置技术降低深度神经网络训练计算成本的方法。研究表明,该方法可减少计算成本40%和训练时间39%。同时,提出了迭代神经突触流剪枝算法(SynFlow),在无训练数据的情况下有效识别稀疏子网络。研究还探讨了剪枝对训练的影响及优化方法,提出双层优化的BiP模型修剪方法,显著提升了速度和效率。
本研究提出了一种新型卷积神经网络剪枝算法,显著降低能量消耗并提高准确性。通过保留权重矩阵的前k个元素,提升学习效率。同时,介绍了Sparse CNN加速器,利用零值权重和激活来提高性能和能源效率。研究探讨了深度学习模型在准确性与能耗之间的权衡,强调优化模型效率的重要性。
Compresso通过合作的剪枝算法和大型语言模型自身,成功将LLaMA-7B剪枝至5.4B,并在多个基准测试上获得更高分数。
完成下面两步后,将自动完成登录并继续当前操作。