
OLAP – 第三阶段压缩
Kimserey Lam’s website, Software Development blog posts, videos and tutorials
·

视频技术领域的静默革命
实时互动网
·
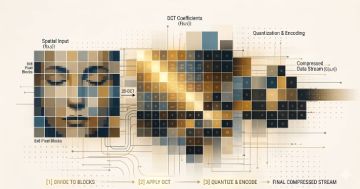
从像素到DNA:为什么压缩的未来关乎所有类型的数据
实时互动网
·

释放新的可能性:压缩和高密度工作流程如何影响体育直播制作
实时互动网
·

大数据中的数据压缩:类型与技术
DEV Community
·

第47天:部署的模型压缩
DEV Community
·

