

向量嵌入解析:从理论到实际应用
Redis Blog
·

AI购物助手:工作原理及构建指南
Redis Blog
·

Data Graphs如何构建真正的混合图RAG平台
Qdrant - Vector Database
·

什么是pgvector?
Databricks
·
向量嵌入生成器:工作原理及使用方法
Redis Blog
·
你的pgvector基准测试为何会误导你
The New Stack
·

SaaS中的语义搜索:当关键词不足以满足需求时
Redis Blog
·

LLM应用的语义缓存:降低成本40-80%,提升速度250倍
Percona Database Performance Blog
·
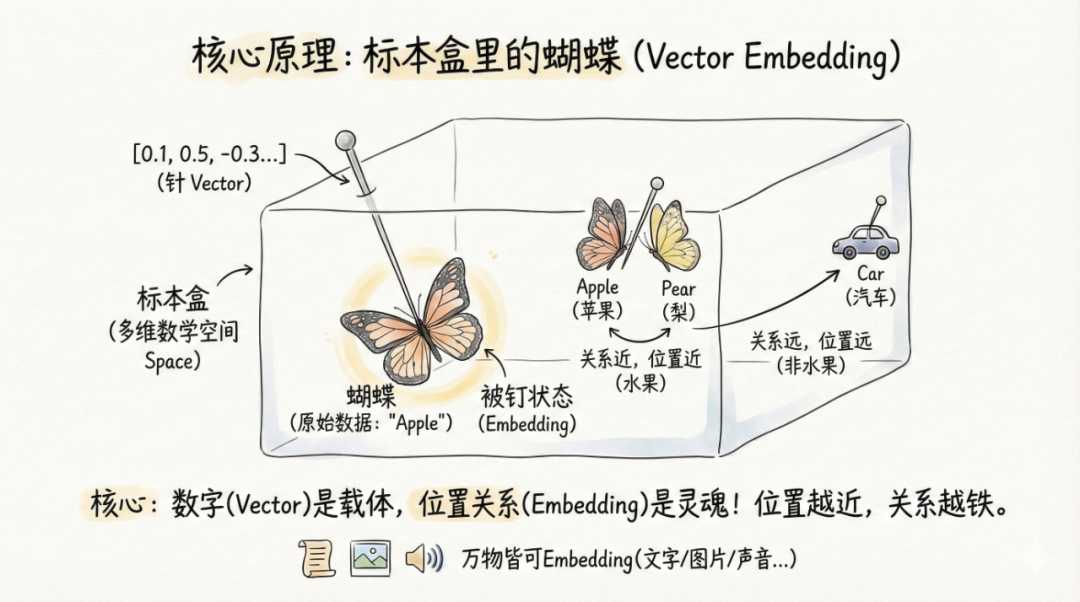
学习 AI 的最大障碍,不懂大模型背后的灵魂
dotNET跨平台
·

RAG 教程笔记(Task03)
程序员充电站
·

戴夫·佩奇:使用PostgreSQL构建RAG服务器 - 第2部分:文档分块与嵌入
Planet PostgreSQL
·
戴夫·佩奇:使用PostgreSQL构建RAG服务器 - 第1部分:加载您的内容
Planet PostgreSQL
·

从零开始构建简单检索增强生成(RAG)系统的七个步骤
KDnuggets
·

如何掌握向量数据库
The New Stack
·

使用Go、Azure Cosmos DB和OpenAI轻松生成向量嵌入
DEV Community
·

解读人工智能术语:开发者理解基础知识指南
DEV Community
·

如何在 Node.js 中创建向量嵌入
DEV Community
·

智能代理中的内存缓存与语义缓存:何时使用哪种?
DEV Community
·

为什么向量量化对人工智能工作负载至关重要
MongoDB
·

Pgai Vectorizer与Python的结合:集成SQLAlchemy和Alembic
Timescale Blog
·
