
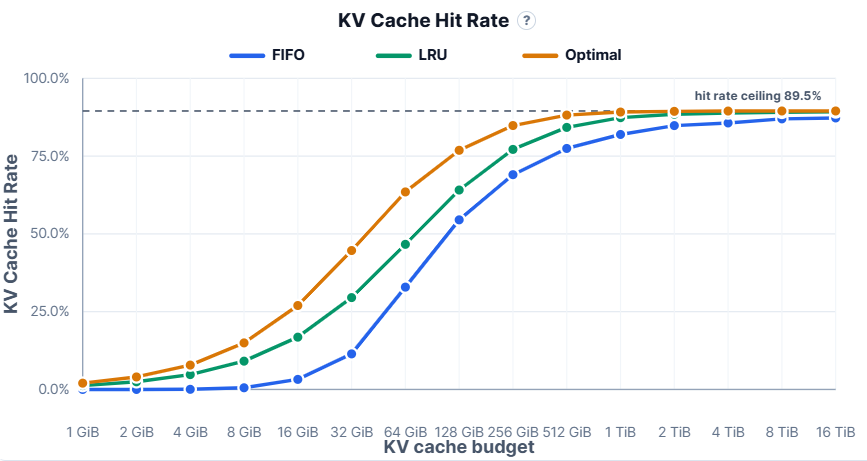
我们需要多少KV缓存预算来支持LLM服务?
Home | KVCache.ai
·
KV缓存命中率模拟器
Home | KVCache.ai
·


SpecMD:关于推测性专家预取的综合研究
Apple Machine Learning Research
·

为什么你的缓存命中率策略需要更新
Redis Blog
·

揭开缓存内存的神秘面纱:技术深度解析
DEV Community
·

【Rust日报】2024-04-19 Egui 能够用于生产了吗?
Rust.cc
·
