
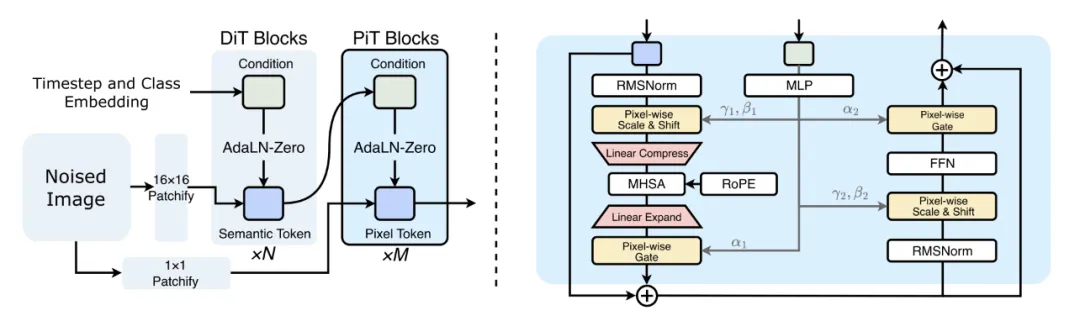

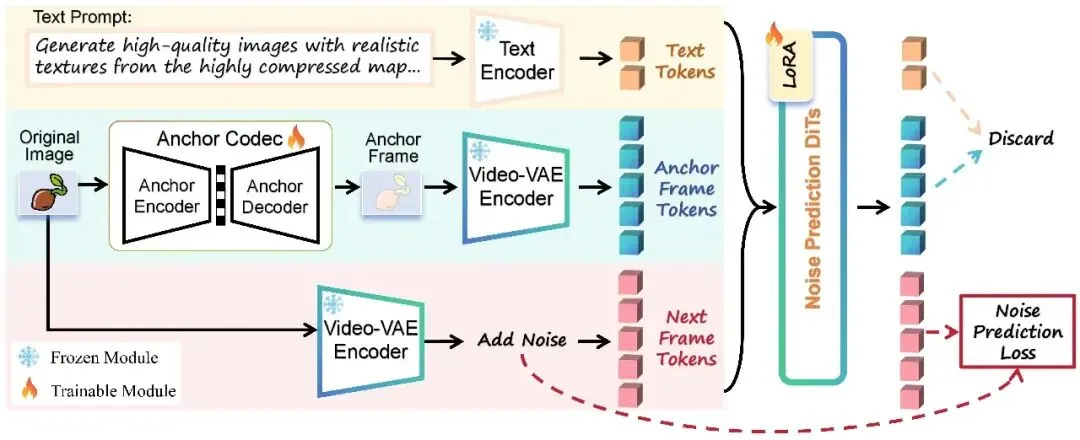

一层就足够:将预训练视觉编码器适应于图像生成
Apple Machine Learning Research
·

如何使用JavaScript构建基于浏览器的PDF图像提取工具
freeCodeCamp.org
·

Meta关闭了允许用户制作公共账户AI深度伪造图像的Instagram功能
The Verge
·

字节跳动发布多模态图像创作模型Seedream 5.0 Pro 生图更懂设计
TechWeb 全站精华
·
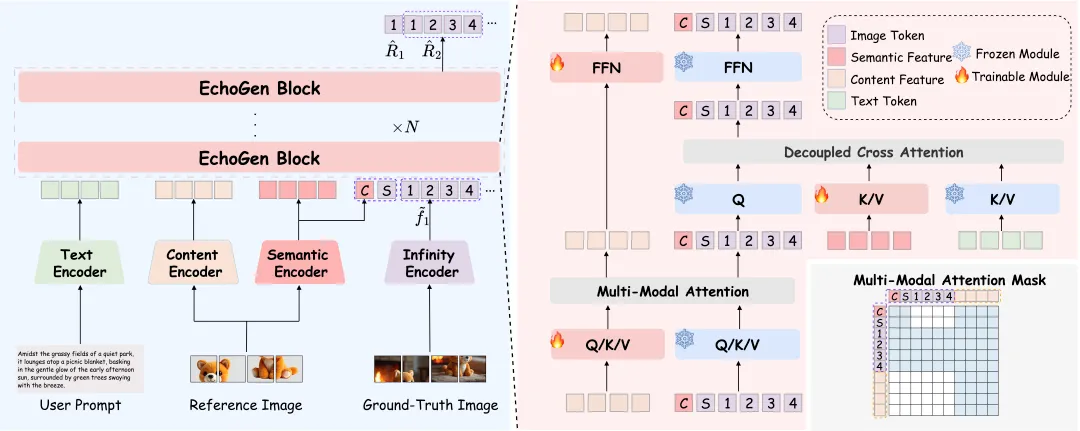
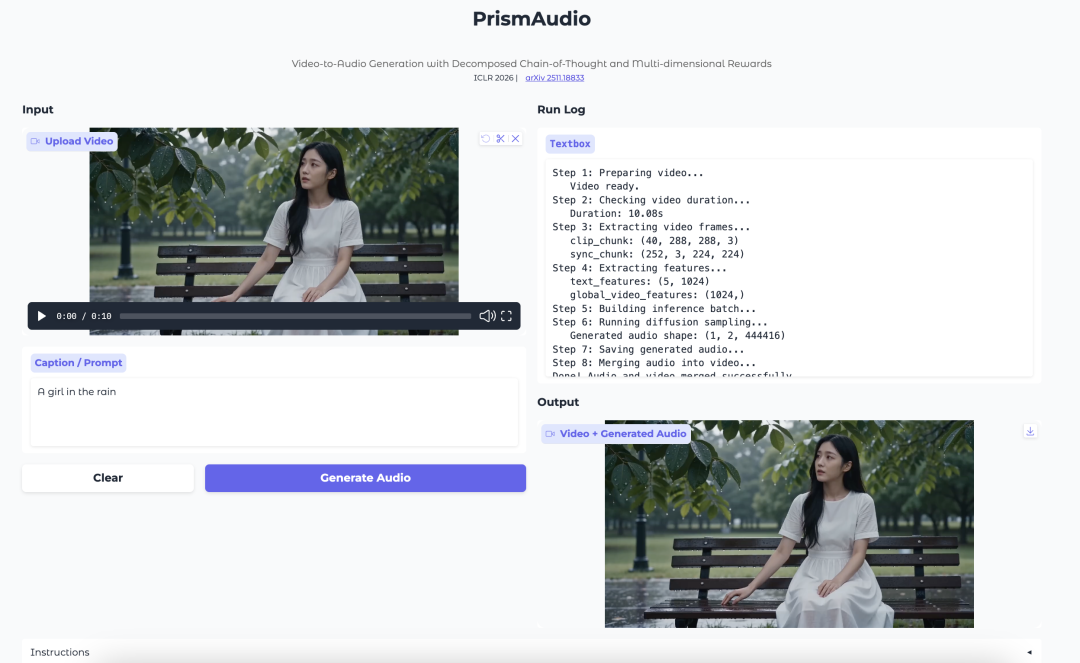

五个开放源代码的全能AI模型:处理文本、图像、音频和视频
KDnuggets
·

徕卡6690美元的SL3-P相机配备4400万像素静态图像与8K视频
The Verge
·

如何在Google Sheets中插入图像
freeCodeCamp.org
·


如何在Node.js中使用QVAC和Socket.io构建离线AI图像生成器
freeCodeCamp.org
·
