
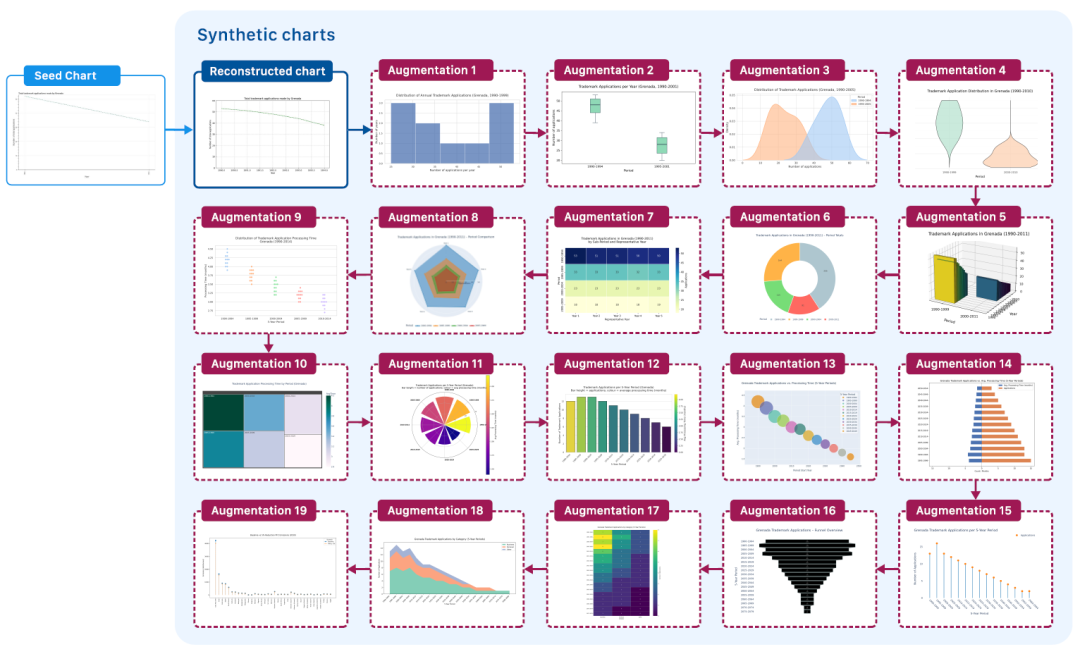
麻省理工/IBM提出迄今为止最大的合成图表数据集ChartNet,生成150万个多样化图表样本
HyperAI超神经
·
麻省理工学院研究人员教AI模型解读图表
MIT News - Computer Science and Artificial Intelligence Laboratory (CSAIL)
·

EncQA:基于视觉编码的图表视觉语言模型基准评估
Apple Machine Learning Research
·


