

思瑞浦打造覆盖高精度电压基准产品的完整产品矩阵
全球TMT-美通国际
·
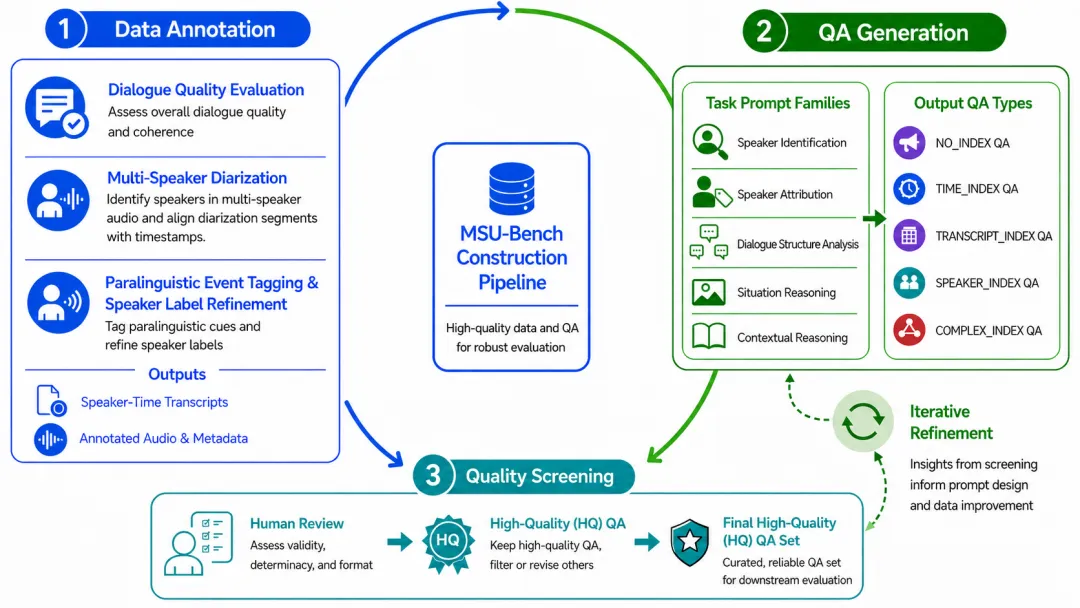

GPT-5.6系列模型的社区反馈、基准表现和使用建议
浮云翩迁之间
·

企业AI基准存在问题
The New Stack
·

一分钟读论文:《AgentGym2——从理想化基准到真实世界部署的评估范式转移》
Micropaper
·

Mayur B.: 我不诚实的基准
Planet PostgreSQL
·
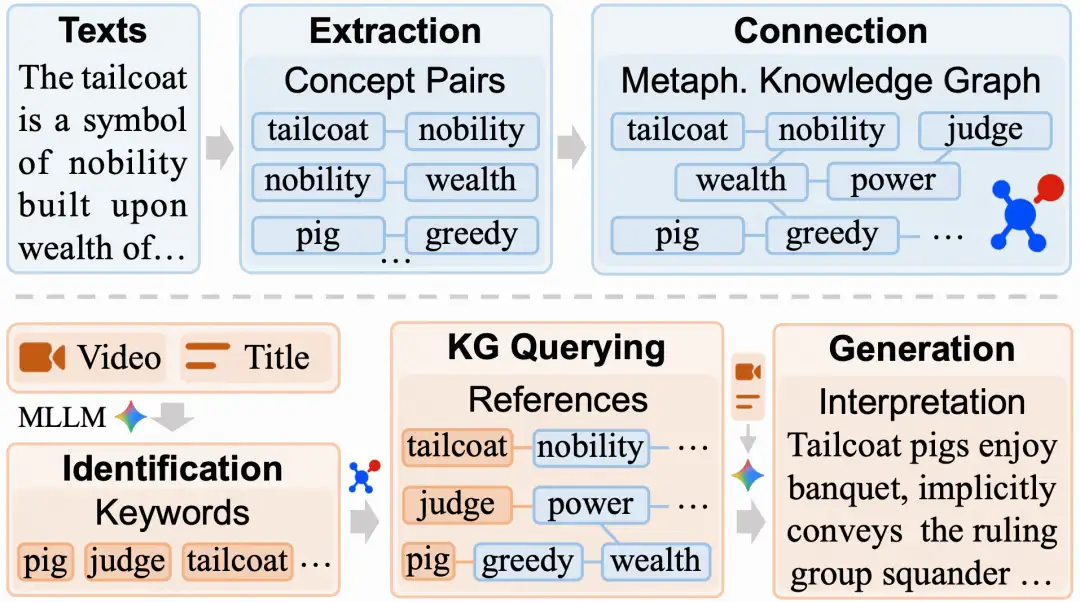

我们一直在错误地衡量AI;为什么经济价值工作是新的基准
The New Stack
·

AI 范式雷达:《Agent评估新标准:用A2A+MCP协议实现基准即Agent》
Micropaper
·

教育直播SDK具备哪些功能?从能力清单看选型基准
实时互动网
·

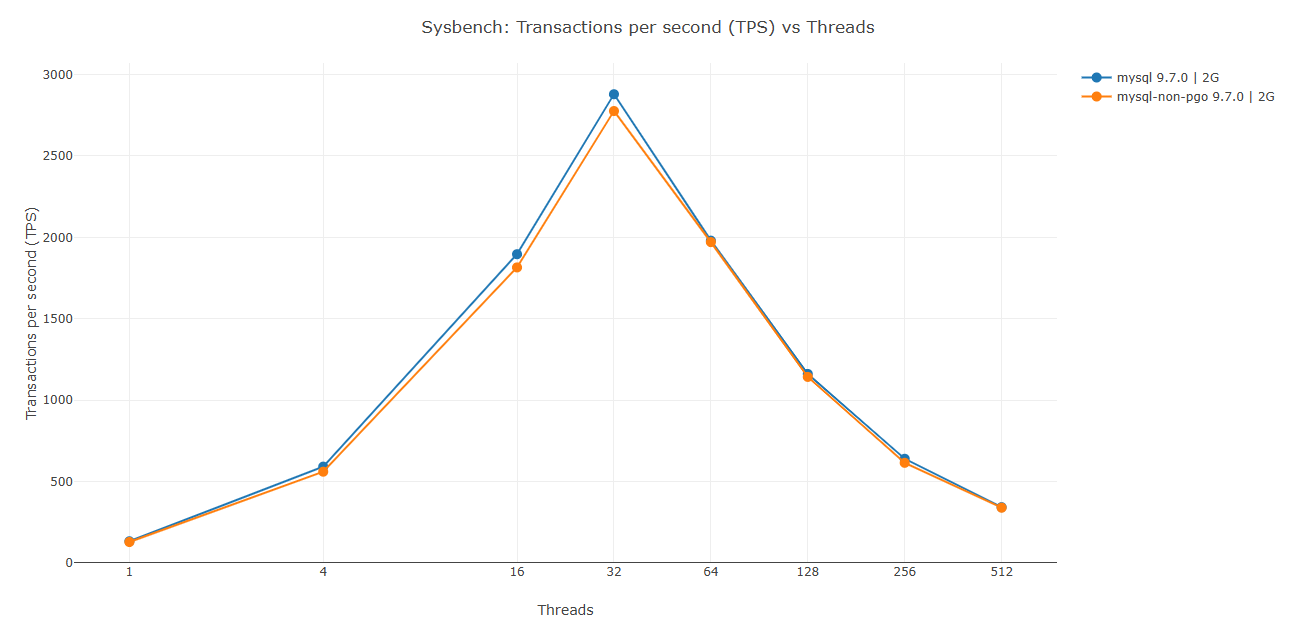
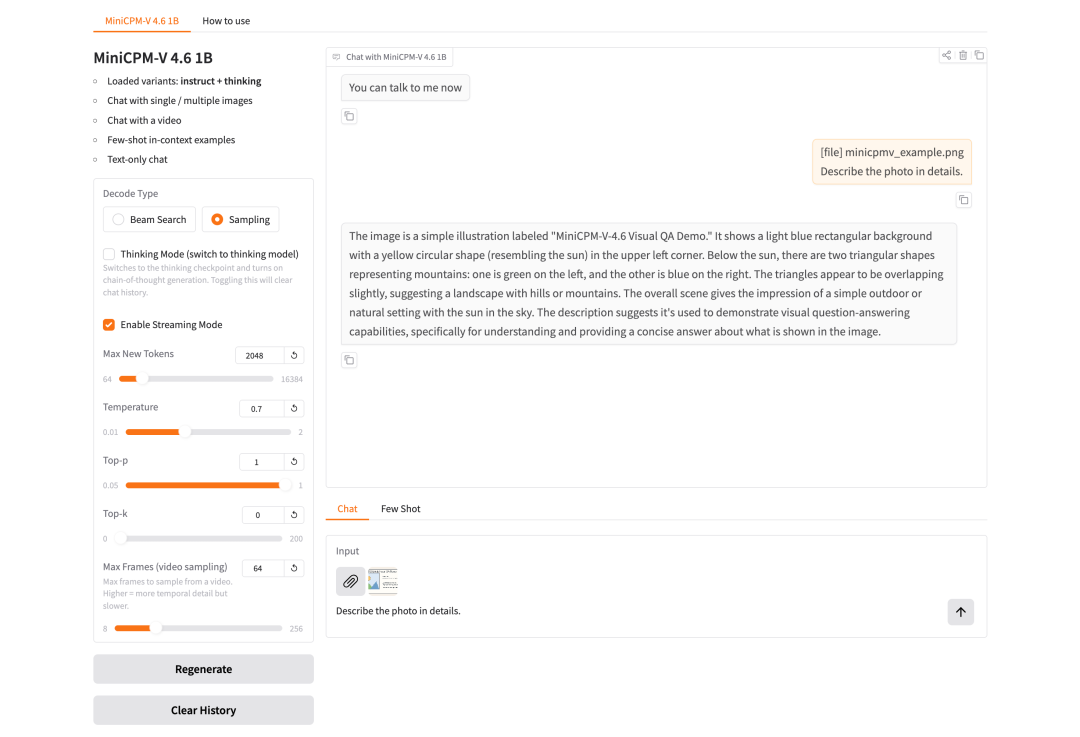

大语言模型速度基准:指标与基础设施指南
Redis Blog
·


从事物的位置到它们的用途:多模态大语言模型的空间–功能智能基准评估
Apple Machine Learning Research
·

提高`nvptx64-nvidia-cuda`目标的基准
Rust Blog
·
