

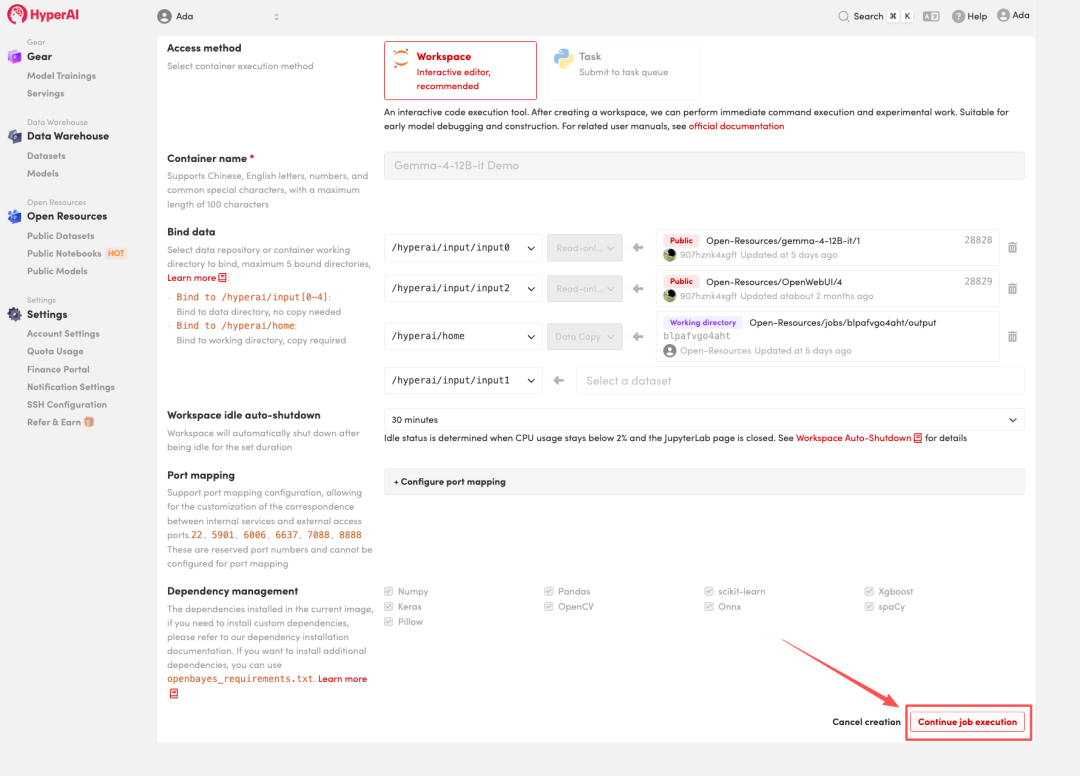

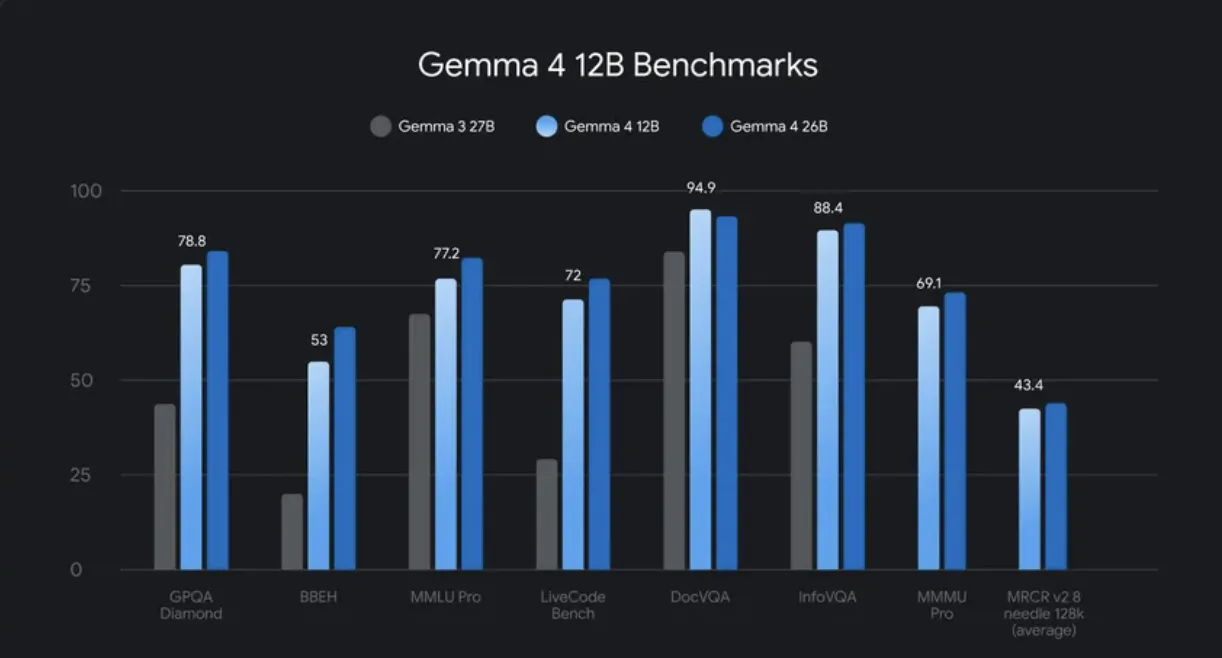
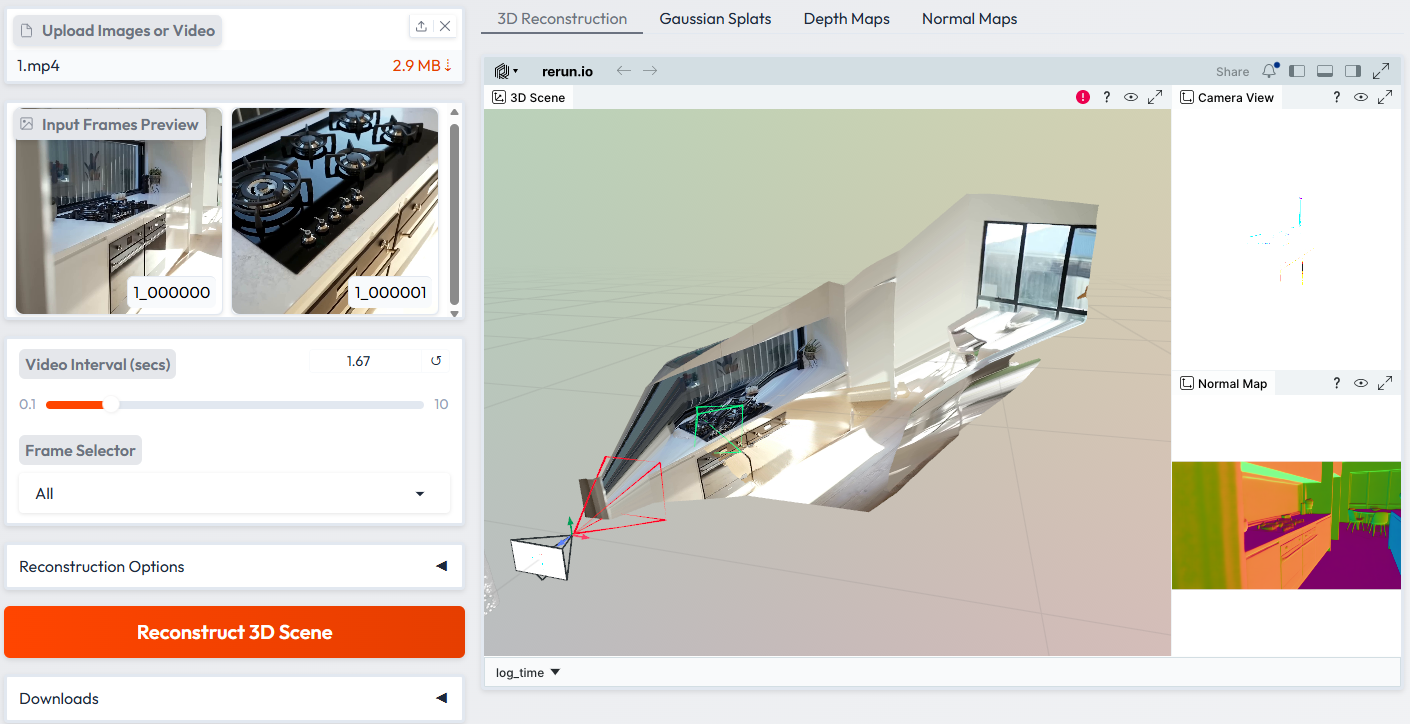


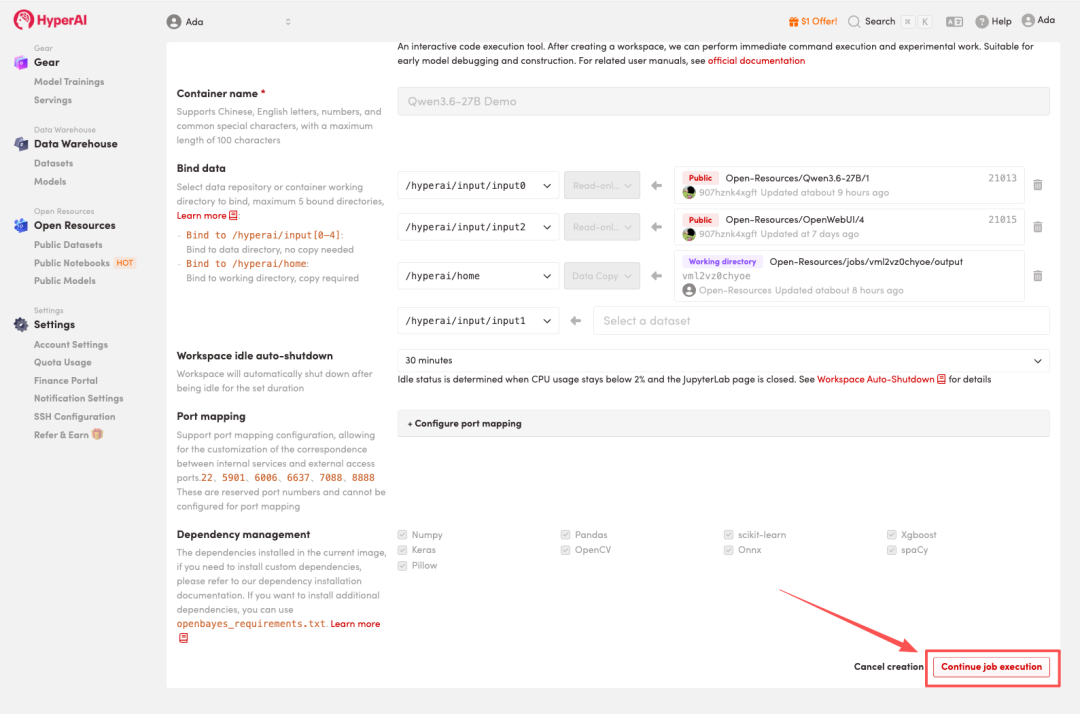
在线教程丨小身材大「码」力,Qwen3.6-27B编程能力达旗舰级
HyperAI超神经
·


苹果在ICLR 2026的机器学习研究
Apple Machine Learning Research
·

学习下大神的知识库
Nicksxs's Blog
·





