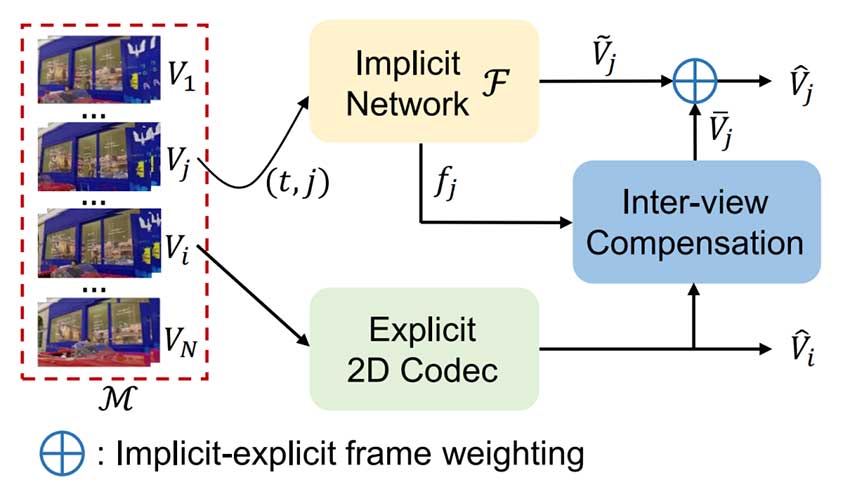
随着3D显示和虚拟现实技术的发展,多视角视频的压缩面临挑战。本文提出了一种隐式-显式集成的压缩方法,结合2D编解码器与隐式神经表示,显著提升了压缩性能和重建质量。实验结果表明,该方法在视角压缩方面优于现有标准。
本研究提出DrivePhysica模型,旨在解决自动驾驶中的高质量多视角视频生成问题。通过三个创新模块,显著提升了视频质量和感知任务的表现。
本研究提出CAT4D方法,填补了从单目视频生成4D场景的技术空白。该方法结合多视角视频扩散模型和新采样技术,实现了精准的4D重建,并在新视角合成和动态场景重建方面表现出色。
本研究提出了一种弱监督方法,旨在解决多视角视频中选择最具信息量视角的问题。通过分析视频相关的语言,发现依赖字幕的视图可以有效作为最佳视角的伪标签,从而显著提升视角选择性能。
本文介绍了AvatarGen方法,该方法利用2D图像生成高保真度可控人体动画。通过结合3D高斯分布点技术,显著提高了训练和推理速度,并在多视角视频中实现高质量重建。此外,研究提出的新型流程有效解决了多视角方法在密切交互人群姿态估计中的困难,提升了鲁棒性和精度。实验结果表明,该方法在几何和外观重建上达到了先进水平。
介绍了名为MVSparse的多人跟踪框架,通过选择信息块来减少计算负载和通信开销,优化多视角视频的利用。实验证明,MVSparse加速了推理时间,轻微损失了跟踪准确性,展示了在多摄像头跟踪应用中的潜力。
该研究提出了一种解决多视角视频中实时渲染问题的方法,通过使用可动态化的人体模型,实现了更好的图像质量和更快的渲染速度。
该论文提出了一种基于多视角视频的多视角一致半监督学习框架,利用未经注释、未校准但同步的多视角视频中的姿态信息相似性作为额外的弱监督信号来引导3D人体姿势回归。通过硬负采样建立多视角一致的姿态嵌入,并结合有限的3D姿态注释来完善该模型,实现了视角不变的姿态检索。
本文介绍了一种综合的神经方法,用于从多视角视频中重建、压缩和渲染人类表演。该方法结合了传统的动画网格工作流和高效的神经技术,包括神经表面重构器和混合神经跟踪器。它还实现了从动态纹理到光图渲染的渲染方案,适用于不同带宽设置。该方法在各种网格应用和平台上展示了逼真的自由视点体验。
完成下面两步后,将自动完成登录并继续当前操作。